This work is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0
International License.
Deze tekst is een bewerking van het artikel op Emerce door Naser Bakhshi, Titus Sloet tot Everlo en Hicham El Bouazzaoui
In dit tweede deel uit een vijfdelige serie over AI zullen we de volgende fundamentele AI-technieken gaan bespreken: Heuristics, Support Vector Machines, neurale netwerken, het Markov beslissingsproces en natuurlijke taalverwerking. In het eerste deel legden we de meest gebruikte definities van AI uit.
Stel dat we munten hebben van 5, 4, 3 en 1 cent (meerdere van één soort). We moeten berekenen hoeveel munten we minimaal nodig hebben om op 7 cent uit te komen. De techniek die we gebruiken om dit probleem op te lossen, noemen we ‘Heuristiek’.
Het Amerikaanse woordenboek Webster definieert de term ‘Heuristiek’ als volgt: het betrekken van of als hulpmiddel dienen bij het leren, ontdekken of oplossen van problemen door gebruik te maken van experimentele en voornamelijk proefondervindelijke methoden. In de praktijk betekent dit dat wanneer het te moeilijk wordt om met exacte deterministische methodes de best mogelijke oplossingen te vinden voor problemen, heuristiek als een van de probabilistische methodes de mogelijkheid biedt om een praktische methode toe te passen waarmee een oplossing bij benadering gevonden kan worden. Een oplossing die weliswaar niet noodzakelijk optimaal is, maar die in de juiste richting kan wijzen.
Voor sommige problemen kan toegepaste heuristiek ontworpen worden om een patroon binnen het probleem te vinden. Een voorbeeld van toegepaste heuristiek voor het munten probleem is ‘hebzuchtige heuristiek’ ook wel “greedy heuristic” genoemd. We spreken van hebzuchtige heuristiek als we altijd kiezen voor de grootst mogelijke denominatie( waarde van betaalmiddel ) en hiermee doorgaan tot we de gewenste waarde van 7 krijgen. In ons voorbeeld betekent dit dat we beginnen met de munt van 5 cent. Voor de overige twee centen is de grootste denominatie die we kunnen kiezen 1 cent. We komen nu nog 1 cent te kort en om dit op te lossen gebruiken we weer een munt van 1 cent.
De hebzuchtige heuristiek heeft ons een oplossing gegeven van 3 munten (5, 1, 1) om tot de waarde van 7 cent te komen. Er bestaat natuurlijk een betere oplossing waarbij we slechts twee munten gebruiken, namelijk de munten van 3 en 4 cent. De hebzuchtige heuristiek biedt niet de beste oplossing voor dit specifieke probleem, maar in de meeste gevallen zal het resultaat acceptabel zijn.
Behalve toegepaste heuristiek voor specifieke problemen, bestaat er ook algemene heuristiek. Net zoals bij neurale netwerken zijn een aantal voorbeelden van algemene heuristiek gebaseerd op processen in de natuur. Twee voorbeelden van dergelijke algemene heuristiek zijn o.a. zwermintelligentiesystemen ( zoals mierenkolonie-optimalisatie , nederlands, code PWS? ) en genetische algoritmes ( voorbeeld ). Het eerste voorbeeld is gebaseerd op hoe eenvoudig mieren samenwerken om samen complexe problemen op te lossen. Het tweede voorbeeld is gebaseerd op het principe waarbij het recht van de sterkste geldt.
Een typisch probleem waarbij heuristiek wordt toegepast om snel acceptabele oplossingen te vinden is rit- en routeplanning. Hierbij is het doel om routes te vinden voor een of meerdere voertuigen die een aantal locaties moeten bezoeken.
De vraag of een e-mail spam of geen spam is, is een voorbeeld van een classificatieprobleem. In dit soort problemen wil men bepalen of een bepaald datapunt tot een bepaalde klasse behoort of niet. Na eerst een classificatiemodel te trainen op datapunten waarbij de classificatie bekend is (bijvoorbeeld een reeks e-mails die gemarkeerd zijn als spam of die juist geen spam zijn), kunnen we dit model daarna gebruiken om de classificatie van nieuwe, onbekende datapunten te bepalen. Een krachtige techniek voor dit soort problemen heet Support Vector Machines (SVM).
De kerngedachte achter SVM is dat je probeert de grenslijn te vinden die de twee klassen scheidt, maar op zo’n manier dat de grenslijn zorgt voor maximale afscheiding tussen deze klassen. Om dit duidelijk te maken gebruiken we de onderstaande eenvoudige gegevens voor ons classificeringsprobleem:
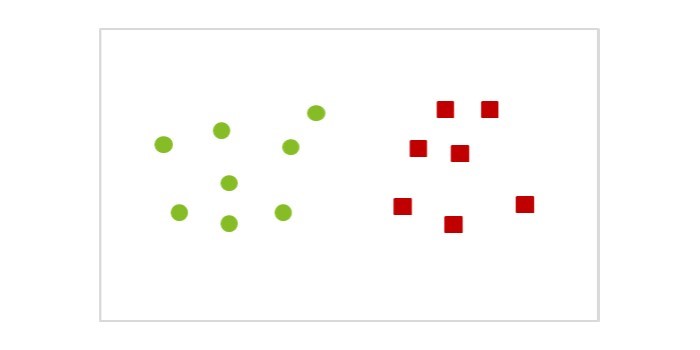
In dit voorbeeld stellen de groene cirkels en de rode vierkanten twee verschillende segmenten voor van het totaal aan klanten (bijvoorbeeld klanten met hoge potentie en klanten met lage potentie), waarbij dit geheel gebaseerd is op allerlei soorten eigenschappen voor iedere klant. Elke lijn die de groene cirkels scheidt van de rode vierkanten wordt beschouwd als een geldige scheidingslijn voor het classificatieprobleem. Er bestaat een oneindig aantal van dit soort lijnen die getekend kunnen worden. Er worden hieronder vier verschillende voorbeelden getoond:
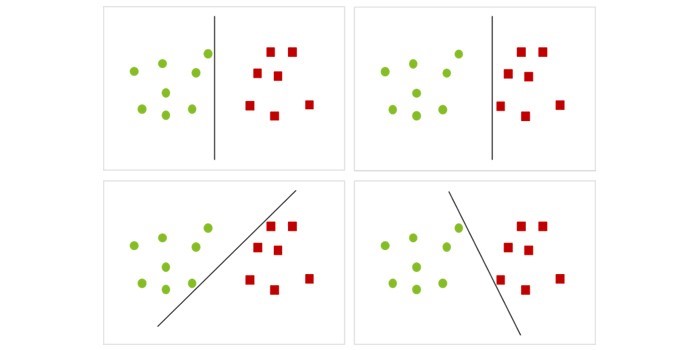
Zoals eerder werd aangegeven, helpt SVM met het vinden van de scheidingslijn die de scheiding tussen de twee klassen optimaliseert. In het gegeven voorbeeld kan dit als volgt worden weergegeven:
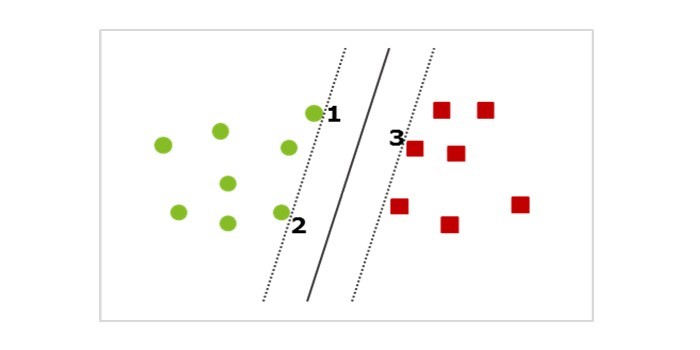
De twee gestippelde lijnen zijn de twee parallelle scheidingslijnen waar de grootste ruimte tussen zit. De daadwerkelijke classificeringsscheiding die gebruikt wordt, is de ononderbroken lijn die zich precies in het midden van de twee gestippelde lijnen bevindt.
De naam Support Vector Machine is afkomstig van de datapunten die zich precies op een van deze lijnen bevinden. Deze lijnen zijn de supporting vectors. In ons voorbeeld waren er drie supporting vectors.
Als een van de andere datapunten (d.w.z. datapunten die geen supporting vector zijn) een beetje wordt verschoven, zal dit weinig invloed hebben op de gestippelde lijnen. Als echter de positie van een van de supporting vectors enigszins wordt veranderd (datapunt 1 wordt bijvoorbeeld een stukje naar links verplaatst), dan zal de positie van de gestippelde scheidingslijnen zeker veranderen en daarmee ook de positie van de ononderbroken classificatielijn.
In de werkelijkheid zijn de datapunten niet zo eenvoudig te scheiden als in dit simpele voorbeeld. Normaal gesproken zijn meer dan twee dimensies betrokken bij de analyse. Behalve rechte scheidingslijnen is SVM in staat om berekeningen uit te voeren die resulteren in niet-lineaire scheidingslijnen. Hiermee kan SVM ook niet lineaire problemen redelijk goed classificeren.
Classificeringsmodellen van een SVM worden ook gebruikt in beeldherkenning, bijvoorbeeld gezichtsherkenning, of wanneer handgeschreven tekst wordt omgezet in getypte tekst.
Dieren en mensen kunnen (o.a. visuele) informatie uit hun omgeving verwerken en zich aanpassen aan de verandering. Voor dit soort gedrag gebruiken ze hun zenuwstelsel. Het zenuwstelsel van de dieren kan gemodelleerd en nagebootst worden en het zou mogelijk moeten zijn om soortgelijk gedrag na te bootsen of te genereren in kunstmatige systemen. Kunstmatige neurale netwerken (Artificial Neural Networks, ANN) kunnen worden omschreven als verwerkingsapparaten die gebaseerd zijn op de neurale hersenstructuur. Het grootste verschil tussen de twee is dat ANN misschien honderd tot duizend neuronen heeft, terwijl de neurale hersenstructuur van een dier of mens er miljarden heeft.
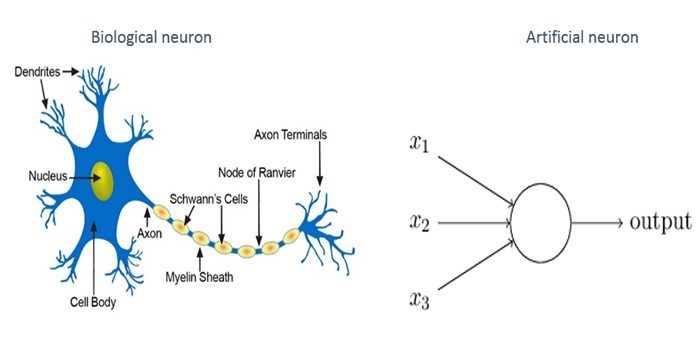
Het basisprincipe van een neurale structuur is dat elke neuron met een bepaalde sterkte aan andere neuronen verbonden is. Gebaseerd op de inputs die worden genomen van de output van andere neuronen (waarbij ook rekening wordt gehouden met de verbindingskracht), wordt er een output gegenereerd die weer gebruikt kan worden als input door andere neuronen, zie Figuur 4 (links). Dit eenvoudige idee is vertaald naar een kunstmatig neuraal netwerk waarbij gebruik wordt gemaakt van gewichten die de sterkte van de verbinding tussen neuronen weergeeft. Bovendien neemt elke neuron de output van de verbonden neuronen als input en gebruiken ze een wiskundige functie om diens output te bepalen. Deze output wordt dan weer gebruikt door andere neuronen.
In het biologische brein wordt leren tot stand gebracht door de verbinding tussen verschillende neuronen te versterken of te verzwakken, terwijl in ANN leren tot stand wordt gebracht door het gewicht tussen de neuronen te veranderen. Door het neurale netwerk een groot aantal sets trainingsdata met bekende eigenschappen te geven, kunnen we berekenen wat de beste gewichten zijn tussen de kunstmatige neuronen, zodat het neurale netwerk de eigenschappen optimaal herkent.
De neuronen van een ANN kunnen worden gestructureerd in verschillende lagen. Figuur 5 geeft een overzichtelijk schema weer van dit soort lagen. Het netwerk bevat een inputlaag waarin alle inputs worden ontvangen en verwerkt, en vervolgens omgezet worden naar outputs voor de volgende lagen. De verborgen lagen bevatten een of meerdere lagen van neuronen die elk door inputs en outputs gaan. Uiteindelijk ontvangt de outputlaag de inputs van de laatste verborgen laag en zet de outputlaag de inputs om in de output voor de gebruiker.
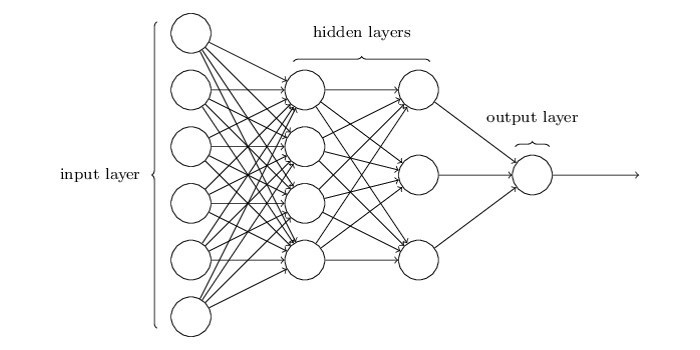
Figuur 5 geeft een voorbeeld weer van een netwerk waarin alle neuronen in een laag verbonden zijn met alle neuronen in de volgende laag. Zo’n netwerk wordt volledig verbonden genoemd. Afhankelijk van het soort probleem dat je wilt oplossen, zijn er verschillende verbindingspatronen beschikbaar. Voor beeldherkenning worden normaal gesproken convolutienetwerken (convolutional networks) gebruikt, waarin enkel neuronen van één laag verbonden zijn met groepen neuronen in de volgende laag (extra). Voor spraakherkenningsdoeleinden worden normaal gesproken teruggekoppelde netwerken (recurrent networks) gebruikt waarin neuronen in een latere laag in een loop terug kunnen gaan naar een eerdere laag.
Andere links:
Neurale netwerken: De beslissende kracht achter internet
Een Markov beslissingsproces (Markov Decision Process, MDP) is een raamwerk voor besluitvormingsmodellen waar in sommige situaties het resultaat gedeeltelijk wordt gebaseerd op de input van de besluitvormer. andere toepassing waar MDP gebruikt wordt is optimale planning. Het fundamentele doel van een MDP is het vinden van een beleid voor de besluitvormer waarin wordt aangegeven in welke toestand welke specifieke actie ondernomen moet worden. Een MDP-model bestaat uit de volgende onderdelen:
Zodra de MDP vastgesteld is, kan er een beleid worden getraind door gebruik te maken van “waarde-iteratie” of “beleidsiteratie”. Deze methoden worden gebruikt om de verwachte beloningen te berekenen voor elk van deze toestanden. Het resulterende beleid levert dan van elke toestand de beste actie die genomen kan worden.
Om een voorbeeld te geven zullen we een raster maken dat een ideale, beperkte wereld voor een robot voorstelt. Dit voorbeeld wordt weergegeven in Figuur 6.
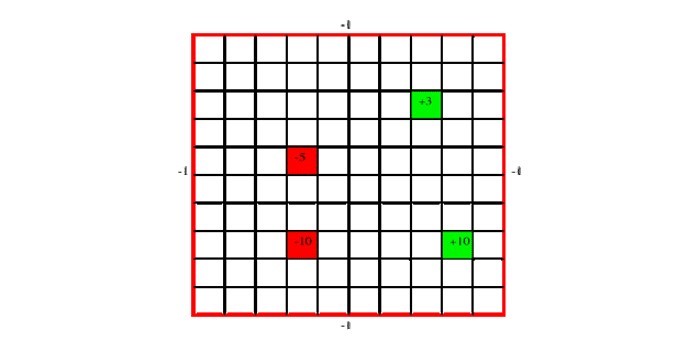
De robot kan van elke positie in het raster (toestand) in vier richtingen bewegen (actie): noord, oost, west en zuid. De waarschijnlijkheid dat de robot naar de gewenste richting gaat is 0,7 en 0,1 als het naar een van de overige drie richtingen gaat. Een beloning van -1 (bijvoorbeeld een strafpunt) wordt gegeven als de robot tegen een muur stoot en als hij niet beweegt. Er zijn tevens bijkomende beloningen en straffen als de robot cellen bereikt die respectievelijk groen en rood gekleurd zijn. Gebaseerd op de waarschijnlijkheid en de beloningen kan er een beleid (functie) gemaakt worden door de oorspronkelijke en laatste toestand te gebruiken.
Een ander voorbeeld waarin gebruik wordt gemaakt van MDP is het probleem van voorraadplanning – een voorraadbeheerder of manager moet bepalen hoeveel eenheden elke week besteld moeten worden. De voorraadplanning kan gemodelleerd worden als een MDP, waar de toestanden beschouwd kunnen worden als een positieve inventaris en tekorten. Mogelijke acties zijn bijvoorbeeld het bestellen van nieuwe eenheden of het verwerken van de achterstand voor de aankomende week. Beloningen – of in dit geval, kosten – zijn normaal gesproken bestelkosten voor eenheden en inventariskosten.
Natural Language Processing ofwel NLP wordt gebruikt om te verwijzen naar alle technieken die te maken hebben met natuurlijke taalverwerking; van spraakherkenning tot taalgeneratie, waarbij elk van deze onderdelen een andere techniek vereist. Een aantal van de belangrijke technieken zullen hieronder uitgelegd worden, bijvoorbeeld Part-of-Speech tagging, Named Entity Recognition en Parsing.
Laten we de volgende zin eens nader bekijken: ‘John hit the can' (John raakte het blik). Een van de eerste stappen van NLP is lexicale analyse, waarbij gebruikt wordt gemaakt van Part-of-Speech (PoS) tagging . Met deze techniek wordt elk woord gemarkeerd om een overeenkomst te vinden met een categorie woorden die vergelijkbare grammaticale eigenschappen hebben. Hierbij wordt uitgegaan van de relatie van dat woord met aansluitende en gerelateerde woorden. Niet alleen woorden worden gemarkeerd, maar ook alinea’s en zinnen.
Part-of-Speech tagging wordt hoofdzakelijk uitgevoerd met statistische modellen die
leiden tot probabilistische resultaten in plaats van deterministische “wat-als”-regels en wordt daarom
gebruikt voor het verwerken van onbekende tekst. Ook kunnen deze statistische modellen omgaan met de
mogelijkheid dat er in plaats van slechts één
Antwoord meerdere
Antwoorden mogelijk zijn; een techniek
die vaak gebruikt wordt voor het markeren is het Hidden Markov-model (HMM).
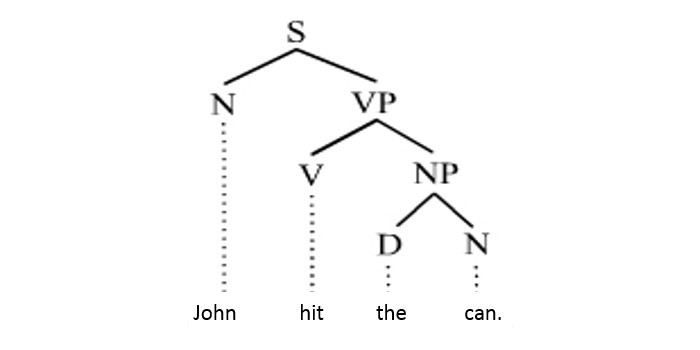
Een HMM is vergelijkbaar met het Markov beslissingsproces, waar elke toestand een gedeelte is van de uiting. De uitkomst van het proces zijn de woorden in de zin. Een HMM ‘herinnert zich’ de volgorde van de woorden die vooraf gingen. Hierdoor kunnen zij beter inschatten welk deel van de uiting (Part-Of-Speech) een woord is. In het eerder genoemde voorbeeld is het waarschijnlijker dat het woord “can” in “hit the can” een zelfstandig naamwoord is dan een werkwoord. Het eindresultaat is dat de woorden als volgt gemarkeerd zijn: ‘John’ als zelfstandig naamwoord (Engels: noun, N), ‘hit’ als werkwoord (Engels: verb, V), ‘the’ als determinator (Engels: determiner, D) en ‘can’ tevens als zelfstandig naamwoord (N).
Named Entity Recognition of NER is vergelijkbaar met POS-tagging, maar in plaats van het markeren van woorden met de functie die zij innemen in een zin (POS), worden de woorden gemarkeerd met het soort entiteit dat zij voorstellen. Deze entiteiten kunnen bijvoorbeeld personen, bedrijven, tijd of locatie zijn. Maar ook meer gespecialiseerde entiteiten zoals gen of proteïne. Hoewel een HMM ook gebruikt kan worden voor NER is de aangewezen techniek voor NER een Recurrent Neural Network (RNN). Een RNN is een van de type neurale netwerken zoals al eerder besproken werd, maar dit netwerk neemt sequenties als input (een aantal woorden in een zin of complete zinnen) en herinnert zich de output van de vorige zin. In de zin ‘John hit the can’ zal RNN het woord John herkennen als de entiteit ‘persoon’.
Een laatste techniek om te bespreken is Parsing (syntactische analyse) – het analyseren van de grammatica en de manier waarop de woorden worden geordend zodat de relaties tussen woorden duidelijk zijn. De Part-of-Speech-tag van de lexicale analyse wordt gebruikt en daarna ingedeeld in kleinere gedeeltes die dan weer gecombineerd kunnen worden met andere zinnen of woorden om een iets langere zin te maken. Dit wordt herhaald totdat het doel is bereikt: elk woord in de zin is gebruikt. De regels over hoe de woorden kunnen worden ingedeeld noemt men grammatica en kan er als volgt uitzien: D+N=NP waar D voor determinator (o.a lidwoorden) staat en N voor zelfstandig naamwoord (noun). Samen wordt het beschouwd als een naamwoordgroep (noun phrase). Wordt het werkwoord (verb) eraan toegevoegd dan wordt het een werkwoordgroep (verb phrase). Het uiteindelijke resultaat wordt weergegeven in onderstaande figuur.
De technieken die gebruikt worden binnen het domein van kunstmatige intelligentie zijn eigenlijk enkel geavanceerde vormen van statistische en wiskundige modellen. Als al deze modellen slim in elkaar gezet worden, kunnen ze ons de tools aanbieden om taken te berekenen die voorheen alleen door mensen konden worden verricht.