source
Overgenomen uit CS Principles: Big Data
en de Lesmodule Big Data ontwikkeld voor Stichting Leerplan Ontwikkeling
De aftrap: (20 minuten)
Bekijk de volgende video: Speelt de video hier niet af ga dan naar Ted
Activiteit: (30 minuten)
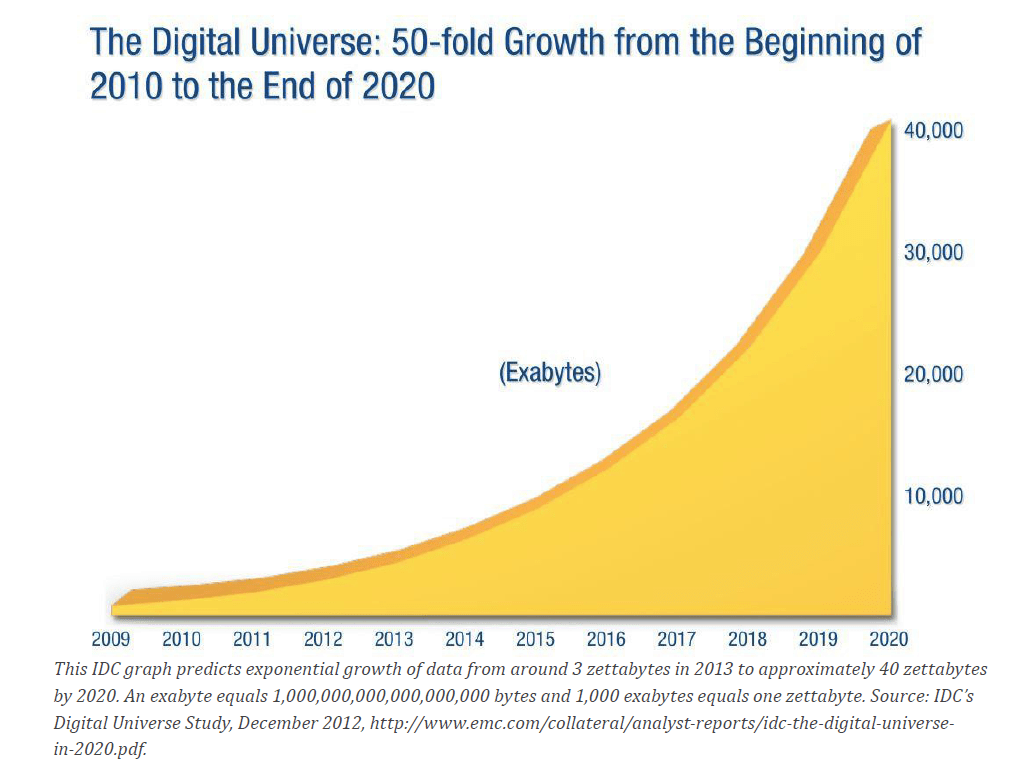
Een deel van de grootte van "Big Data" wordt alleen al verklaard door de enorme toename van data in de wereld. Bekijk maar eens goed de grafiek hierboven. Je ziet in de grafiek dat de hoeveelheid data die in de wereld aanwezig is exponentieel toeneemt. Ongeveer iedere twee jaar is er een verdubbeling. Dit betekent ondermeer dat de mensheid in de komende twee jaar net zoveel data produceert als dat er tot dit moment door de hele mensheid in alle voorgaande tijden is verkregen. Na die twee jaar gebeurt dat de volgende twee jaar weer en zo maar door. Dat is geweldig veel.
De wet van Moore: Gordon Moore deed 1965 een voorspelling dat de rekenkracht van computers iedere 1.5-2 jaar zal verdubbelen. Deze voorspelling is tot nu toe ongeveer uitgekomen. De toename van data verloopt blijkbaar ook volgens de wet van Moore.
There is a principle in computer science known as Moore's Law.
It is not a law of nature or mathematics but simply a surprisingly accurate prediction that was made a long time ago. In 1965, a computer chip designer named Gordon Moore predicted that the number of transistors one could fit on a chip would double every 18 months or so.
Amazingly, that prediction has more or less held true to the present day! The result is that since about 1970, computers have gotten twice as fast, at half the cost, roughly every 1.5-2 years. With some small differences, the same is true for data storage capacity.
This is extraordinarly fast growth - we call it exponential growth. With more and more machines that are faster and faster, the amount of data being pushed around, saved, and processed is growing exponentially. This is so fast that it's hard to fathom and even harder to plan for. For example:
Key Takeaway: We need to keep Moore’s Law in mind as we plan for the future.
Big data is overal maar het is soms een verbazingwekkend grote uitdaging om toegang tot de data te krijgen, het te gebruiken of te zien. Veel van de data ligt voor het oprapen. Zelfs wanneer de data "toegangkelijk" is, is het een uitdaging om uit te zoeken waar de data vandaan komt en hoe de data gebruikt kan worden.
Opdracht: Je krijgt in tweetallen
één van de volgende site's ter onderzoeking aangewezen. Beantwoordt voor de aangewezen site de vragen op de
Big Data detective kaart en verwerk
de tabel in jullie website.
Web Sites:
Afronding: (20 minuten)
Vraag: (10 minuten) Wat denk je dat, na je verkenningen, "big data" precies betekent? Wat maakt "big" in tegenstelling tot "niet big"?
Doel: Het doel van van de discusie is je vertrouwd te maken met de verschillende vormen van gegevens en hoe die worden gebruikt. Je hebt gezien dat het visualiseren (in beeld brengen) van grote verzamelingen van gegevens belankrijk is.
Wat maakt "big" in tegenstelling tot "niet big" is een lastige vraag want a) "big data" heeft geen vaste definitie - of data "big" is hangt vaak af van de context waarin de data een rol speelt of hoe de data wordt geruikt - en b) zelfs experts kunnen het lastig vinden om het precies te duiden. In de aanvullende theorie hieronder vind je de belangrijkste drie eigenschappen die bepalen of data big is.
Data verzamel je voor informatie, maar soms levert de verzamelde data onvoorziene resultaten die weer leiden tot nieuwe technieken. Ben je voorbeelden tegengekomen waarbij je reactie was "Wat een fantastische toepassing van de data?"
Aanvullende theorie: (30 minuten) bron:Lesmodule Big Data
Big Data betekent letterlijk ‘grote data’. Maar wanneer is groot nu eigenlijk groot?
Voor een mier is een takje groot, maar een olifant kan met bomen spelen.
Wat vroeger als veel informatie werd beschouwd, is een lachertje voor moderne computers.
Data is pas werkelijk Big Data als er nieuwe manieren en technieken nodig zijn om geld te verdienen
met behulp van deze data. Deze strikte definitie van Big Data wordt over het algemeen niet gebruikt
als men over Big Data spreekt.
Data is pas echt groot als het voldoet aan drie kenmerken. Deze kenmerken zijn hoeveelheid, snelheid,
en diversiteit.
Deze drie kenmerken worden verder uitgewerkt.
| Naam | Waarde | Binair | Waarde |
|---|---|---|---|
| Byte | 1 = 100 | Byte | 1 = 20 |
| Kilobyte | 1.000 = 103 | Kibibyte | 1.024 = 210 |
| Megabyte | 1.000.000 = 106 | Mebibyte | 1.048.576 = 220 |
| Gigabyte | 1.000.000.000 = 109 | Gibibyte | 1.073.741.824 = 230 |
| Terabyte | 1.000.000.000.000 = 1012 | Tebibyte | 1.099.511.627.776 = 240 |
| Petabyte | 1.000.000.000.000.000 = 1015 | Pebibyte | 1.125.899.906.842.624 = 250 |
| Exabyte | 1.000.000.000.000.000.000 = 1018 | Exbibyte | 1.152.921.504.606.846.976 = 260 |
Het eerste kenmerk van Big Data is de hoeveelheid data.
Bij natuurkunde heb je vast al kennis gemaakt met de voorvoegsels ‘kilo’ en ‘mega’.
Deze worden bij computers ook gebruikt om duizenden of miljoenen bytes op een gemakkelijk manier op te schrijven.
Er is alleen een probleem bij het gebruiken van bytes om deze om te zetten naar duizendtallen.
Als je namelijk gebruik maakt van binair rekenen, kom je niet uit op 1.000 bytes = 1 kilobyte, maar 1.024 bytes = 1 kilobytes.
Daarom is afgesproken dat bij binair rekenen je niet ‘kilo’ en ‘mega’ gebruikt, maar ‘kibi’ en ‘mebi’.
In de praktijk wordt nog steeds gebruik gemaakt van ‘kilo’ en ‘mega’,
maar dit is dus niet de exacte hoeveel opslag die er daadwerkelijk is. Bekijk de tabel maar eens.
Je ziet dat er weinig verschil is. Daarentegen bij hogere machten, bij ‘peta’ en ‘exa’ loopt het verschil op in meer dan 10%!
Als je een harde schijf koopt van 1 terabyte, bevat deze in werkelijkheid geen 1.099.511.627.776 = 240 maar
1.000.000.000.000 = 1012 bytes. Dit is een significant verschil.
Omdat in het in het taalgebruik is ingeburgerd en omdat je op deze manier minder kunt verkopen voor dezelfde
prijs wordt nu nog steeds over terabytes gesproken in plaats van de wiskundige tebibytes.
Sanne wil berekenen hoeveel dataopslag er nodig is om alle namen de gebruikers van Facebook op te slaan. Ga ervanuit dat Facebook 1.86 miljard gebruikers heeft. Ga er verder vanuit dat de lengte van de naam van gebruiker gemiddeld 16 tekens (= 16 bytes) bevat.
Henk heeft een camera opgehangen om zijn buurman in de gaten te houden. Hij wil de beelden graag 200 dagen lang bewaren. De camera slaat 4 beelden per seconde op met een resolutie van 1024 x 768 pixels (=beeldpunten).
Het tweede kenmerk van Big Data is de snelheid om de data op te vragen. Bekijk het onderstaande voorbeeld.
Sofie wil de gemiddelde leeftijd berekenen van alle Facebook gebruikers. Ga ervanuit dat Facebook 1.86 miljard gebruikers heeft. Ga er verder vanuit dat er 8 bits nodig zijn per leeftijd.
De harde schijf waarop de data is opgeslagen heeft een leessnelheid van 10 megabytes per seconde.
Een smartphone of computer heeft maar een bepaalde ruimte om data op te slaan. Uit een eerder besproken voorbeeld blijkt dat er 19 tebibytes nodig zijn om voor 200 dagen kleurenvideo op te slaan. Op het moment dat deze module is geschreven kan één harde schijf maximaal 10 tebibytes bevatten. Er zijn dus 2 harde schijven nodig om zoveel data op te slaan. Deze passen net in een enkele PC. Bij nog meer data kun je wel een netwerk bouwen met meerdere PC’s, waarbij elke PC een gedeelte van de opslag voor zijn rekening neemt. Bekijk nu het volgende voorbeeld.
Chris wil de gemiddelde kleur weten van alle pixels van 2000 dagen kleurenvideo. Deze kleurenvideo heeft een opslag nodig van 190 tebibytes. Hiervoor heeft hij 20 PC’s ingezet, elk met een opslagcapaciteit van 10 tebibytes.
De PC waarop Chris de berekening uitvoert, heeft een verbinding met deze 20 PC’s, en het is mogelijk om 500 mebibytes per seconde te transporteren over deze verbinding.
Chris heeft bedacht dat het veel slimmer is om de gemiddelde kleur te berekenen op de PC waarop de videobeelden zelf staan.
Vervolgens wordt de waarde gestuurd via de verbinding naar de PC waarop Chris de berekening heeft gestart.
De reden dat dit veel sneller is komt omdat er geen gebruik meer gemaakt hoeft te worden van een trage netwerkverbinding.
De data kan direct in de PC getransporteerd worden naar de centrale berekeningseenheid in een PC.
Een ander woord voor dit onderdeel is de processor van de computer, of de CPU (Central Processing Unit).
Stel dat je dus 20 PC’s hebt. De snelheid van de processor om het gemiddelde te bereken van bits is 250 gebibtyes per seconde.
Deze manier van berekenen wordt ook wel distributed computing genoemd. Deze techniek is een goed voorbeeld van techniek die ontwikkeld is en verder ontwikkelt moet worden om Big Data snel genoeg te kunnen verwerken.
| # | vorm |
|---|---|
| 1 | Driehoek |
| 2 | Vierkant |
| 3 | Vierkant |
| 4 | Ster |
| # | kleur |
|---|---|
| 1 | geel |
| 2,4 | rood |
| 3 | blauw |
| # | kleur |
|---|---|
| 1 | geel |
| 2 | rood |
| 3 | blauw |
| 4 | rood |
Het derde kenmerk van Big Data heeft alles te maken met de diversiteit van de data.
Als data weinig divers is, is het gemakkelijk om de data te analyseren en om de gegevens uit de data te halen die je wilt.
Kijk maar naar de tabel "Data in de normale representatie".
Je kunt zien dat de data weinig divers is. Er zijn vier objecten, en elke object heeft een kleur.
Als je het objectnummer weet, kun je gemakkelijk nagaan wat de bijbehorende kleur is.
Andersom is iets lastiger, maar nog steeds doenlijk. De kleur ‘geel’ hoort bij object 1, de kleur ‘blauw’ hoort bij object 3,
en de kleur rood hoort bij de objecten 2 en 4.
Bekijk nu ook "Data in een andere representatie". Als je beide tabellen met elkaar vergelijkt,
zie je dat de tweede tabel meer diversiteit aan data bevat.
De tweede kolom van de tweede bevat namelijk complexere data, namelijk een lijst met objecten in plaats van een enkel object.
In de eerste tabel is de data minder divers, omdat elk object een eigen kleur heeft.
Overigens is de data van beide tabellen even divers, alleen de representatie van de data is anders.
Hierdoor komt de diversiteit van de data beter tot haar recht. De diversiteit van data is niet afhankelijk van hoe de data is gerepresenteerd.
Daarom loont het altijd om eerst de data op de juiste manier te representeren voordat je gaat onderzoeken hoe divers de data is.
| # | kleur | vorm | video |
|---|---|---|---|
| 1 | geel | Driehoek | 24 frames |
| 2 | rood | Vierkant | 48 frames |
| 3 | blauw | Vierkant | 24 frames |
| 4 | rood | Ster | 24 frames |
| # | kleur | vorm |
|---|---|---|
| 1 | geel | Driehoek |
| 2 | rood | Vierkant |
| 3 | blauw | Vierkant |
| 4 | rood | Ster |
Je kunt je voorstellen dat er meer data bekend is van elk object. Bekijk tabel Diverse data.
Elk object heeft ook een vorm. Data fusion maakt het mogelijk om de gegevens van de objecten te combineren. Het woord ‘fusion’ komt van fuseren, wat samenvoegen, samensmelten betekent. Bekijk de volgende tabel maar, waar de data is samengevoegd.
Een mooi voorbeeld van de diversiteit in data kun je vinden in tabel Meer diverse data. In de laatste kolom zie je dat er een videofragment is toegevoegd aan elk object.
Stel dat we nu alleen de video hebben, en we gaan op zoek bij welk object de video hoort. Als de video 48 frames heeft, is het een gemakkelijk taak in dit geval, dan hoort de video bij object 2. Als de video 24 frames heeft, wordt het erg ingewikkeld. We moeten dan de bits in de video op de een of andere manier gaan analyseren om erachter te komen bij welk object de video hoort. Een mogelijke aanpak is om de waardes van de rode, groene en blauwe kleur van alle pixels in de video op te tellen. Hopelijk heeft object 1 minder rode pixels dan object 3 en 4. Als dat niet het geval is, moeten we nog een complexere oplossing bedenken. Dit is een goed voorbeeld waaruit blijkt dat de diversiteit van data een rol speelt in de definitie van Big Data. Data is pas echt groot als het moeilijk is te analyseren, of als alleen via een complexe manier het mogelijk is de juiste gegevens uit de data te halen.
Gegeven tabel Meer diverse data.