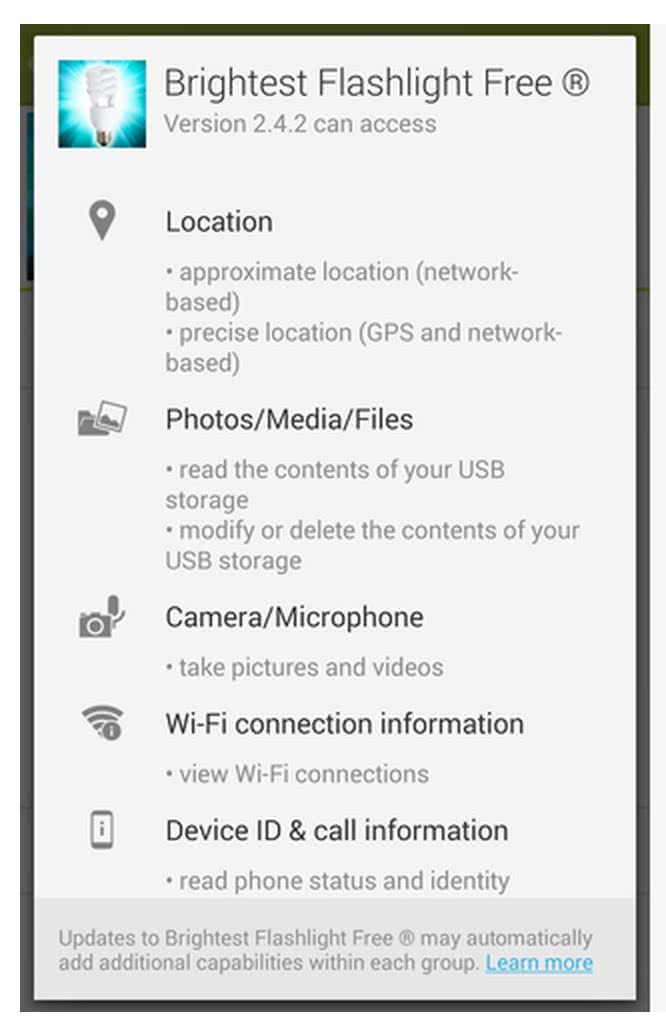
 Zou jij deze app installeren?
Je gaat de app hiernaast op je telefoon installeren. Wat is je reactie op het scherm hiernaast?
Zou jij deze app installeren?
Je gaat de app hiernaast op je telefoon installeren. Wat is je reactie op het scherm hiernaast?
- Welke vragen heb je?
- Wat zou je willen weten?
- Wat ga je doen om dit uit te vinden?
- Zou je deze app installeren?
Overgenomen uit CS Principles: Big Data
De aftrap: (15 minuten)
Niet alleen Nederlanders zijn gierig. Bijna ieder mens wil de dingen die hij/zij nodig heeft gratis. Daarnaast wil iedereen veel geld verdienen. Zo ook dus de eigenaars en ontwikkelaars van vele gratis diensten en apps op het internet. Er zijn overheden of door overheden gesubsidieerde instellingen (b.v. universiteiten) die gratis software beschikbaar stellen die met behulp van belastinggeld worden gemaakt. Ook zijn er hobbyisten en bedrijven die het leuk vinden om een bijdrage te leveren aan de ontwikkeling van gratis software.
Echter wie wil verdienen aan gratis zal ergens zijn financiën vandaan willen halen. Niet verwonderlijk is dat de gebruiker van de ontwikkelde producten daar voor moet gaan zorgen. Die levert bewust of vaker nog onbewust een schat aan gegevens aan de eigenaren van de aangeboden diensten. We geven bij het aanmelden en bij gebruik al heel vaak bewust informatie die ons eventueel kan schaden. Maar hoeveel gegevens worden er nu eigenlijk over ons verzameld zonder dat wij het weten?
Zeker nu computers steeds sneller worden en er verschrikkelijk veel van zijn wordt het steeds makkelijker om data te vergaren en te gebruiken voor een veelheid van doelen. Na dit hoofdstuk heb je inzicht in de mechanismen gekregen waarmee er aan jou gegevens wordt verdient.
Bekijk de volgende video of de eerste 6 minuten van de tweede als je het Engels te lastig vindt:De video's vertellen hoe je mobiele telefoon en de websites die je bezoekt bepaalde dingen over jou volgen. We willen hier wat meer van weten. We zullen ons toespitsen op de volgende vragen:
Opdracht:
Activiteit 1: (30 minuten)
Lees het artikel Users Get as Much as They Give of de Nederlandse vertaling Gebruikers Krijgen net Zoveel als Zij Geven.Opdracht: Start een discussie in jullie scrumgroep over de volgende punten en verwerk die in een html document voor jullie site.
Activiteit 2: Lees een echt privacybeleid (30 minuten)
Opdracht:Kies per persoon één van de mobiele apps die je veel gebruikt of hebt bekeken in de vorige activiteit en ga op zoek naar het document dat het privacybeleid bevat (b.v. google) en beantwoord de volgende vagen:
Afronding: (5 minuten)
Zou jij deze app installeren?
Je gaat de app hiernaast op je telefoon installeren. Wat is je reactie op het scherm hiernaast?
Aanvullende theorie: (45 minuten) bron:Lesmodule Big Data
In bovenstaande opdrachten heb je zelf of samen met je groep een beeld gevormd van Big Data, de toepassingen, de voorbeelden en de problemen. In onderstaande tekst pogen we dit beeld preciezer te maken. Echter volledig kunnen we nooit zijn vooral omdat het een groot werkveld betrefteren er bovendien nog zoveel nieuws gebeurd. Veel van onderstaande theorie heb je waarschijnlijk zelf al ontdekt.
Na de uitgebreide definitie van Big Data in de aanvullende theorie van Big Data
is het tijd om meer in detail te gaan kijken naar de toepassingen.
Je zult zien dat Big Data op heel veel verschillende manieren in ons leven een belangrijke rol speelt.
Uit onderzoek van Gartner blijkt bij succesvolle integratie van Big Data dat een bedrijf 20% beter presteert dan concurrerende bedrijven.
Die potentie is er ook voor de publieke sector ondanks dat men daar niet een specifiek winstoogmerk heeft.
Onderzoeker McKinsey stelt zelfs dat Big Data, wanneer juist toegepast, de publieke sector in Europa 150 tot 300 miljard per jaar kan opleveren.
Wat zijn dan die unieke toepassingen binnen de private sector en wat kan de publieke sector daar mee?
In Sneller meten, weten en van feit naar beleid gaan we hier dieper op in.
Hoe onze maatschappij verder vorm krijgt en de potentie heeft tot verduurzaming met behulp van Big Data komt samen met de valkuilen in
Duurzaamheid en privacy aan bod. Uiteindelijk ronden we in De noodzaak en de mensen af met
de steeds belangrijkere rol van Big Data voor organisaties, het soort mensen die hierbij nodig zijn en de opleidingen die daarbij horen.
Misschien heb je na deze module wel zoveel interesse gekregen dat je business analist of
data scientist wil worden!
Met bijna 100 miljoen betalende abonnees heeft Netflix behoorlijk wat informatie van klanten te verwerken om het aanbod te blijven verbeteren. Netflix wil natuurlijk graag films en series aan het assortiment toe blijven voegen waar behoefte naar is. Om die behoeftes in kaart te brengen verzameld Netflix gegevens over ons kijkgedrag: wat kijk je? welke genres? hoe lang? pauzeer je vaak? wanneer precies? hoe lang moest je zoeken? Op basis van deze data mining( het verzamelen van data )kan Netflix persoonlijke aanbevelingen doen, de klant tevreden houden en nog belangrijker: nieuwe klanten werven!
Alleen data verzamelen is niet genoeg om te blijven verbeteren. Hoe weet Netflix op basis van al deze data of een nieuwe film gewild zal zijn? Hiervoor richt Netflix zich op Big Data analytics. Met behulp van Big Data technieken proberen organisaties voorspellingen te doen. Dat is precies wat Netflix ook doet. Door middel van uitgebreide analysetechnieken wordt waardevol inzicht verkregen. Het ingenieuze deel aan de oplossing van Netflix is het gegeven dat het bedrijf klanten uitbetaald om films en series te voorzien van tags. Vervolgens geeft Netflix op basis van jouw streamgedrag en veel voorkomende tags suggesties voor soortgelijke films en series. Zo kan Netflix het aanbod steeds verder verfijnen en blijven leren van haar klanten.
Neem als voorbeeld ‘de zorg’ waarbij, in de meest ideale situatie, alle gegevens van elke operatie en elke patiënt verzameld, verwerkt en geanalyseerd kunnen worden om
Uiteindelijk kan dat tot een betere zorg leiden. Dat hier nog wat haken en ogen aan zitten bespreken we in Duurzaamheid en privacy en De noodzaak en de mensen.
Belangrijk is dat Big Data ons in staat stelt om zogenaamde ‘real time’ ontwikkelingen vanuit verschillende bronnen te volgen en er voortdurend aan te meten. Om zoveel mogelijk nuttige ‘real time’ data te verzamelen worden vaak allerlei sensoren en aan het internet gekoppelde apparaten gebruikt. Dit noemen we ook wel het internet of things (IoT). Je zou IoT kunnen zien als een manier om bij Big Data daadwerkelijk voor de grote hoeveelheid data te zorgen. Al die metingen maken het vervolgens mogelijk om in een vroeg stadium op basis van de beschikbare data voorspellingen te doen zodat problemen kunnen worden voorkomen. Een voorbeeld hiervan is het sturen van mensenstromen op konigsdag in Amsterdam. De zendmasten signaleren de aanwezigheid en verplaatsing van mobiele telefoons. Verhoogt de concentratie van telefoons zich in een bepaalde straat en gaat daarbij de snelheid van verplaatsing van dde telefoons, dan kan de organisatie een paar straten terug de feestvierders in een andere richting sturen om ongelukken te voorkomen.
Een uitgebreide analyse op basis van de data en ondernomen acties zorgt dan voor een beter inzicht en mogelijkheden voor besluitvorming waarbij behoeften en kansen voor verbetering sneller in beeld komen. In plaats van voor iedereen dezelfde acties te ondernemen is het dan mogelijk om maatwerk te leveren en dat op te nemen in het beleid. Uitgebreide analyse op de verzamelde data maakt het zelfs mogelijk om voorspellingen te doen over de haalbaarheid van de te ondernemen actie.
Deze feedback cyclus van meten - inzicht - kansen - actie kan met Big Data snel worden doorlopen en de effecten van een bepaald beleid direct inzichtelijk maken die voorheen niet of nauwelijks afgeleid konden worden door de grote hoeveelheid aan data. Hierdoor is het mogelijk om sneller af te leiden welke delen van het beleid wel of niet effectief zijn, waar nog geoptimaliseerd kan worden zodat er ruimte is voor innovatie. Uiteindelijk kunnen hierdoor weer nieuwe producten en diensten ontstaan. Waar bedrijven voorheen jaren nodig hadden om beleid te evalueren is het met Big Data mogelijk direct te evalueren en aan te passen waardoor innovatieprocessen sterk versneld worden. Een mooi voorbeeld van de uitwerking van deze stappen uit de cyclus is het London Smart City initiative:
Terwijl je dit leest maakt jouw school hoogstwaarschijnlijk ook gebruik van Big Data. Zo zijn er tegenwoordig digitale leeromgevingen en online methodes waar jij als leerling in kunt werken en waar docenten jou in kunnen volgen en indien nodig assisteren. Gegevens over jouw voortgang, zoals welke oefeningen nog niet lukken, hoe lang je ergens over hebt gedaan, kunnen door middel van Learning Analytics zowel de leerling als de docent een beter inzicht geven in de mate van die voortgang, zodat jij beter jouw leerproces kan sturen en de docent jou daar gerichter bij kan helpen!
Behalve het gebruiken van de theorie is het aan te raden om bij onderstaande vragen gebruik te maken van het internet om tot volledige antwoorden te komen.
Uit de voorgaande paragraaf werd al duidelijk dat de inzet van Big Data niet alleen maar voordelen kent en dat er grote verschillen zijn in aanpak tussen de publieke en private sector. Toch zijn er voor beide sectoren veel mogelijkheden op het gebied van duurzaamheid. In alle gevallen moet men veel data verzamelen die soms te herleiden zijn tot een bepaald individu. In deze paragraaf gaan we van de vele duurzame mogelijkheden naar de grootste valkuilen van Big Data.
Het toepassen van procesoptimalisatie om energie en grondstoffen te besparen noemen we verduurzaming door middel van Big Data. Die besparingen kunnen oplopen tot miljoenen euro’s. In de vorige paragraaf zagen we voorbeelden van manieren hoe een succesvolle toepassing van Big Data tot grote besparingen kan leiden. Behalve de verduurzaming in de zorg (zie paragraaf 2) zijn er nog veel meer mogelijkheden. Denk aan de volgende zaken:
Hierbij kun je denken aan windmolens in de zee die worden voorzien van sensoren om de effecten van het weer en het water te meten. Door deze gegevens te analyseren is het mogelijk om vooraf te kunnen bepalen hoe een nieuwe windmolen hierop zal reageren. Bedrijven die de windmolens plaatsen kunnen hiermee rekening houden en er uiteindelijk voor zorgen dat een windmolen langer blijft werken en het windmolenpark dus meer energie op zal leveren.
Men voorspelt hiermee dat de windmolenparken 20% meer energie op kunnen wekken
Hierbij moet je vooral denken aan het begrip precisielandbouw dat zorgt voor een grote revolutie in de agrarische sector. Met behulp van allerlei sensoren die pH-waarden meten in de grond kan uiterst nauwkeurig bepaald worden welk deel van het land meer of minder kalk nodig meer of waar extra bemesting verstandig is. Dit leidt onder andere tot een vermindering in de hoeveelheid kunstmest en bestrijdingsstoffen. Dit is goed voor het milieu en de portemonnee!
Met behulp van aan het internet gekoppelde sensoren (IoT) en computersimulaties is het mogelijk om beter inzicht te krijgen in de werking van een waterzuiveringsinstallatie. Met dit inzicht herkent men de situaties waarin er meer zuurstof, energie of chemicaliën nodig zijn. Door middel van uitgebreide analyse kan de installatie dus op de juiste momenten de juiste stappen ondernemen.
In Spanje is een dergelijk systeem al in werking gegaan, waarbij de toepassing van Big Data zorgde voor 13% minder elektriciteitsconsumptie, 14% minder gebruik van chemicaliën en 17% minder afval.
Naast energiezuinige woningen met besparende kranen, zonnepanelen en slimme meters, zit de echte kracht in de aaneenschakeling en onderlinge afstemming van verschillende apparaten in het huis. In 2017 worden verschillende proeven gedraaid met zogenaamde pilotwoningen die zijn voorzien met allerlei sensoren. Het hoofdsysteem van de woning, genaamd Iris, leert van het gedrag van de bewoners, stemt hier de aansturing van bijvoorbeeld de verwarming op af om uiteindelijk zoveel mogelijk energie te kunnen besparen.
Het is niet ondenkbaar dat jij binnenkort in een ‘slim’ kantoorgebouw komt te werken waarbij met behulp van allerlei sensoren (IoT) data verzameld wordt over beweging, koolstofdioxide gehalte, temperatuur en luchtvochtigheid. Aansturen van systemen als verlichting en ventilatie zorgen dan niet alleen voor energiebesparing, maar ook voor ‘gezondere’ en betere werkplekken die weer voor een verbeterde productiviteit kunnen zorgen!
In de vorige paragraaf werden de mogelijkheden besproken voor verbeteringen in de zorg. Onderzoekers van de Vrije Universiteit in Amsterdam hebben Big Data, in de vorm van geanonimiseerde elektronische patiëntendossiers, daadwerkelijk gebruikt om darmkanker te detecteren. Door een computersysteem de grote hoeveelheden gegevens te laten scannen zijn patronen ontdekt en verbanden gelegd die voorheen nog niet in beeld waren gekomen. Door Big Data is het mogelijk om in de toekomst in een vroeger stadium kanker te constateren.
Bovenstaande lijst is een greep uit de vele mogelijkheden van verduurzaming door middel van Big Data. Door het aanbrengen en inwinnen van informatie afkomstig van sensoren in allerlei situaties is het mogelijk om veel meer inzicht te krijgen over de manier waarop wij omgaan met de grondstoffen die de Aarde ons te bieden heeft en hoe wij daar als mensheid mee om kunnen gaan.
Dit klinkt fantastisch en veel hiervan wordt al gerealiseerd, maar als er overal informatie over ons gedrag wordt ingewonnen, hoe zit het dan met onze privacy?
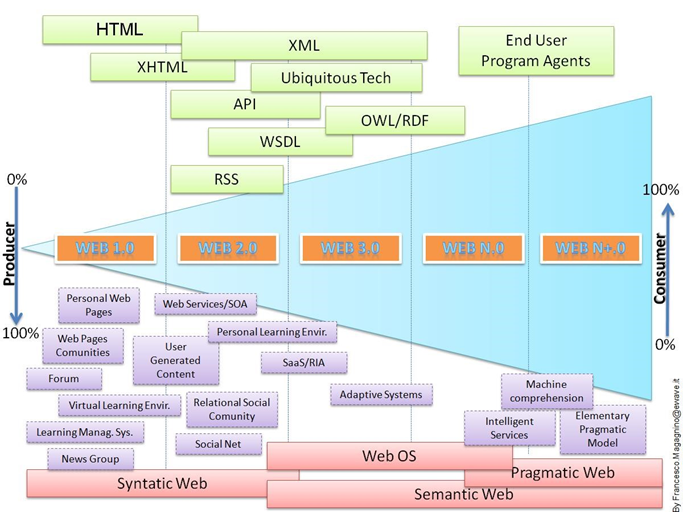
Het internet heeft de afgelopen jaren sterke ontwikkelingen meegemaakt die gekenmerkt kunnen worden door generatienamen als Web 1.0, Web 2.0, Web 3.0 enz. (zie Figuur hiernaast)
Door deze generaties heen heeft de mens steeds meer data zelf gemaakt. In het begin, tijdens Web 1.0, waren vooral hobbyisten actief in het maken van webpagina’s, maar tegenwoordig kan iedereen zo beginnen met het bouwen van een eigen website en ligt de nadruk op online gemeenschappen en socialiseren; mensen (Web 2.0).
Ondertussen zijn we aangekomen in Web 3.0 waar Big Data de grootste rol speelt. Via het Internet of Things (IoT) zijn steeds meer apparaten aan het internet gekoppeld en verzamelen we overal grote hoeveelheden informatie over onze omgeving, producten die we gebruiken, maar vooral ook onszelf.
Op dit moment zien we vooral inzet van die gegevens om allerlei producten te verbeteren, processen te optimaliseren en grotere efficiëntie in b.v. dienstverlening door te voeren. De vraag is dan: hoe ziet een toekomst eruit waarin vrijwel al onze privé-acties op een bepaalde manier worden opgeslagen?
Nu al vraagt men zich af hoe bedrijven als Facebook omgaan met de grote hoeveelheden persoonlijke data, ook wel Big Social Data genoemd. Kunnen wij elkaar daarin nog vertrouwen? Krijgen we bijvoorbeeld inzicht wat er over ons is opgeslagen en waar die data allemaal naartoe gaat? Hoe zit het precies met onze privacy? In de activiteiten in het begin van dit hoofdstuk heb je daar al flink overna gedacht en gediscusieerd.
Iedereen is blij met energiebesparing, kostendalingen, verbeterde dienstverlening, zorg en misdaadpreventie door middel van Big Data, maar als hierbij onze rechten als burger geschonden worden gaat dat te ver. Een belangrijke voorwaarde hierbij is de mogelijkheid om data te kunnen herleiden naar een individu. Het College Bescherming Persoonsgegevens (CBP) houdt zich in Nederland onder andere hier mee bezig. Zij geven bijvoorbeeld aan dat bedrijven niet in alle gevallen toestemming moeten vragen voor het gebruik van naam, adres e.d. Dit soort data noemen we persoonsgegevens omdat op basis daarvan iemand geïdentificeerd kan worden. Als een bedrijf die gegevens nodig heeft voor de normale bedrijfsvoering dan ziet het CBP dat als een ‘gerechtvaardigd belang’.
Wanneer persoonsgegevens geanonimiseerd zijn, zijn zij voor Big Data doeleinden bruikbaar. Als een organisatie gebruik wil maken van herleidbare gegevens moet er zijn voldaan aan de eisen van de Wet bescherming persoonsgegevens (Wbp). Herleidbare gegevens zijn data die het mogelijk maken om jouw identiteit vast te stellen. Deze mogen alleen gebruikt worden voor het doel waarvoor de gegevens zijn verzameld. Het is mogelijk om daar toestemming voor te vragen, maar dan moet iemand zeer goed geïnformeerd zijn en op de hoogte zijn van de manier waarop de gegevens zullen worden gebruikt. De overheid die dergelijke gegevens van ons verzameld heeft naast verantwoordelijkheid voor de beveiliging en juistheid van de gegevens ook de verantwoordelijkheid om de gegevens te anonimiseren zodat er geen sprake meer is van herleidbaarheid.
De wet Wbp, die opgesteld is in 2001; voor het tijdperk van Big Data, was ondanks zijn heldere criteria toe aan vernieuwing. Zo steeg het aantal rechterlijke zaken waarbij overheden op de vingers werden getikt wegens verkeerde toepassing van Big Data op hun burgers. Een overzicht hiervan is op deze site te vinden: https://www.privacyfirst.nl/rechtszaken-1.html . Als opvolger is er sinds 2018 de AVG. Wat het effect is van deze wet op onze privacy moet de tijd nog uitwijzen.
Burgers uiten steeds vaker zorgen over elektronische dataopslag door de overheid. Een bekend voorbeeld is het elektronische patiëntendossier, waarin al de medische gegevens staan van een burger. Je moet maar hopen dat die gegevens niet benaderbaar zijn door de verkeerde personen. Er is veel mogelijk binnen de kaders van de wet, maar niet alles mag zomaar over ons worden bijgehouden en opgeslagen worden. Bedrijven en overheden moeten daarom bewust omgaan met het privacy vraagstuk als het gaat om Big Data.
Het is duidelijk dat een goede inzet van Big Data voor grote verbeteringen in onze maatschappij kan zorgen. Toch zijn er, zoals je in de vorige paragraaf kon lezen, de nodige valkuilen en ziet niet elk bedrijf een noodzaak om te veranderen. Waarom die noodzaak er is gaan we in deze paragraaf bespreken. Bovendien kijken welke mensen en opleidingen daarbij nodig zijn om de aanpassingen in goede banen te leiden.
Uit de vorige paragrafen bleek al dat organisaties goed moeten nadenken over de manier waarop zij data verzamelen en dat bij een correcte inzet ook sprake kan zijn van een verbetering in de beleids- en innovatieprocessen. Voor veel bestaande grote organisaties is dat erg lastig: afdelingen hebben onderlinge afhankelijkheden, weten vaak niet van elkaar wie welke informatie heeft en de informatiebronnen zijn vaak niet of lastig op elkaar af te stemmen wat voor een succesvolle toepassing van Big Data noodzakelijk is.
In de private sector zien we daarom dat nieuwe bedrijven, de zogenaamde startups, de ‘grote jongens’ vaak inhalen doordat klanten tegenwoordig andere diensten en meer maatwerk vragen. Omdat de startups vanaf het begin hun organisatiestructuur hebben opgebouwd aan de hand van de huidige technologische mogelijkheden zijn zij vaak beter in staat om op korte termijn veranderingen door te voeren tegen lagere kosten. Klanten zijn hier vaak erg van gecharmeerd omdat het bedrijf daarmee als het ware meebuigt, snel aanpassingen maakt en dat ook nog tegen een redelijke prijs.
Gezien de afwezigheid van het winstoogmerk is te begrijpen dat van dergelijke ontwikkelingen in de publieke sector minder sprake is. Toch is er ook in de publieke sector een noodzaak om te veranderen. Zo moet men wegens economische druk zoeken naar manieren om kosten te drukken, zodat er enerzijds financiële ruimte is voor vernieuwing maar ook lastenverlichting in de vorm van belasting aan de kant van de burger.
Zo stelt Prof. dr. Theo de Vries van de universiteit Twente dat een nationaal anti-fraudebureau ons land miljarden euro's kan besparen en dat door een correcte inzet van Big Data soortgelijke besparingen elders ook mogelijk zijn.
Het is nu duidelijk geworden dat organisaties moeten vernieuwen, maar waar liggen dan precies de pijnpunten? Hieronder een aantal voorbeelden:
Organisaties moeten veranderen op volgende wijze op deze pijnpunten uit de weg te gaan:
Het is duidelijk dat bij dergelijke veranderingen de rol van managers en bestuurders in het algemeen steeds verder zal afnemen. De nadruk komt te liggen op professionals die de data van het bedrijf kunnen analyseren, inzichten kunnen verschaffen en aan de hand hiervan snel een nieuwe strategie kunnen uitzetten op basis van de data. Dit vereist een feiten (op basis van data) gestuurde organisatie die kortcyclisch bottom-up werkt waar de beleidsmedewerkers zich richting uitvoering begeven. Door inzet van nieuwe technologie en Big Data zal de voorheen gescheiden wereld van beleid en uitvoering verdwijnen en meer integratie van verschillende organisatiedelen plaatsvinden.
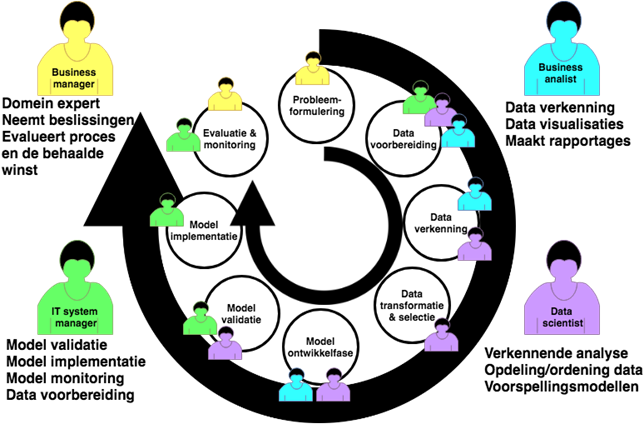
Stel je wil als bedrijf graag uit de grote hoeveelheid beschikbare data inzicht verkrijgen en op basis daarvan voorspellingen doen. Hoe pak je dat dan aan (stappenplan) en wie heb je daarbij nodig (personeel)? Voor de bemensing maken we onderscheid tussen de volgende vier rollen:
Het is natuurlijk ook mogelijk meerdere rollen door eenzelfde persoon worden uitgevoerd.
Die rollen hebben hun taken in de verschillende stappen die nodig voor een goede organisatie van de werkzaamheden.
Het bedrijf heeft een doel voor ogen. In het begin probeert de business manager, om dit doel te bereiken, grip te krijgen op het geheel door alles concreet te maken en het proces af te bakenen.
Zodra het ‘probleem’ goed in beeld is begint krijgen de IT system manager(s), data scientist(s) en business analist(en) de gezamenlijke taak mogelijke databronnen in kaart te brengen. Hierna wordt het geheel gereed gemaakt voor verzameling en opschoning zodat er sprake is van een optimale bruikbaarheid van de data. Omdat hier een combinatie van veel professionals noodzakelijk is heeft deze stap veel tijd nodig.
Bij deze stap zijn de data scientists bezig om met behulp van speciale software de data te doorzoeken op patronen, onderliggende relaties en eventuele trends waar de organisatie het beste op in kan spelen om het doel van het bedrijf te verwezenlijken.
Vervolgens bouwen de data scientists via statistische en data-mining software een algoritmisch model. Hierbij maakt men in veel gevallen gebruik van zelflerende modellen (Artificial Intelligence) die aan de hand van de oude data, telkens aangevuld met bijbehorende nieuwe data, uitkomsten met een hogere voorspellende waarde kunnen genereren. Deze resultaten moeten constant tegen het licht worden gehouden door de business analist om te zien op welke manier het geheel bijdraagt aan het doel dat tijdens de voorbereiding was opgesteld.
Tijdens deze stap voeren de data scientists samen met de IT system manager en achterliggende ICT-ers de laatste checks uit om eventuele fouten in het model op te sporen en de werking vooraf te testen. De daadwerkelijke implementatie en toepassing van het model ligt volledig bij de IT system manager en de bijbehorende IT-ers.
Na de implementatie is het noodzakelijk voor de ontwikkeling van de organisatie om alles te monitoren en op basis van de resultaten de genomen stappen te evalueren en waar nodig te zorgen voor aanpassing. Door nauw overleg tussen de IT system manager en de business manager worden nieuwe doelen gesteld en/of problemen snel geïdentificeerd om vervolgens weer opnieuw de cyclus te doorlopen aan de hand van een bijgewerkte strategie. Het geheel is als cyclus van voorspellende analyse in figuur als volgt weer te geven:
Data scientists hebben vaak een vooropleiding gehad binnen de volgende velden: (toegepaste) wiskunde, statistiek, technische informatica en econometrie.
In Delft bestaat hier bijvoorbeeld de studie Technische Informatica en Technische Wiskunde voor en in Rotterdam de studie Econometrie. Er bestaan tegenwoordig echter ook al zeer gerichte opleidingen op het gebied van data science. Zo biedt de universiteit in Eindhoven de opleiding Data Science aan.
Business analisten en business managers hebben vaak een vooropleiding gehad in de vorm van business management met een combinatie van IT. In Rotterdam bestaat hier bijvoorbeeld de opleiding Business Information Management voor.
Er zijn ook vaak aansluitende masters of minors binnen de opleiding voor Big Data te vinden waardoor iemand zich vanuit het bedrijfsperspectief al kan richten op het werken met Big Data.
IT system managers hebben vaak een vooropleiding gehad in de vorm van informatica of bedrijfskundige informatica. Dergelijke opleidingen worden tegenwoordig door het hele land aangeboden en geven de mogelijkheid om heel breed uit te stromen.
Door het grote aanbod van opleidingen die in meer of mindere mate te maken hebben met Big Data is de afgelopen jaren de nadruk komen liggen op zelfstudie.
Werkgevers vragen vaak om aantoonbare kennis in het gebruik van bepaalde softwarepakketten en/of resultaten van online sites zoals https://bigdatauniversity.com/ , https://www.datacamp.com en https://www.kaggle.com/
Het is daarom belangrijk om naast een opleiding ook goed te blijven kijken naar het online cursusaanbod dat binnen jouw vakgebied en interesses ligt. In de laatste opdracht van deze paragraaf gaan we daar dieper op in.
In de theorie heb je kunnen lezen dat er tegenwoordig steeds meer de nadruk is komen te liggen op zelfstudie via online platformen. Binnen de IT en aansluitende vakgebieden gaan de ontwikkelingen zo hard dat het voor veel werkgevers zelfs een vereiste is om aan te tonen dat jouw vaardigheden en kennis ‘op peil’ zijn.
Sommige van deze cursussen zijn betaald maar er zijn ook veel gratis MOOC’s (Massive Open Online Courses). Binnen Big Data nemen data scientists de meest prominente rol in. Zonder hun uitgebreide kennis van statistiek en computerwetenschappen is het niet mogelijk om de voorspellende modellen te ontwikkelen waar een organisatie op zit te wachten. Er is veel vraag naar hun expertise en veel websites waar de vaardigheden als data scientist aangeleerd kunnen worden laten als stimulans zelfs het gemiddelde salaris zien om mensen aan te trekken.
Neem maar eens een kijkje op de volgende site: URL: https://www.datacamp.com/tracks/data-scientist-with-python
Om je kennis te laten maken met de hoofdconcepten van ‘data science’ gaan we online een beginnerscursus volgen op de site van bigdatauniversity.com. De cursus is in het Engels en levert bij succesvolle afronding een badge/certificaat op. Hoe hoger jouw score binnen de cursus, hoe beter jouw deelcijfer.
De URL: https://bigdatauniversity.com/courses/data-science-101/
Maak een account aan of log in met jouw Google of Facebook account.