
Voordat we een aantal verschillende AI-technieken bekijken, stellen we eerst de vraag: wanneer is het handig om kunstmatige intelligentie te gebruiken en wanneer niet?
Kunstmatige intelligentie heeft volgens de meeste definities iets te maken met het uitvoeren van complexe taken waarvoor intelligentie nodig wordt geacht. Er zijn echter genoeg voorbeelden van software die ook zeer complexe taken uitvoeren door gebruik te maken van heel complexe algoritmen. Voorbeelden hiervan zijn computer algebra systemen (CAS). Met deze systemen kun je wiskundige problemen exact laten doorrekenen. Tijdens je wiskunde toetsen zouden die goed van pas komen. Helaas verboden tijdens examens.
Een ander voorbeeld van complexe software zonder AI kan een robot in een productielijn zijn. Iedere keer wordt zeer precies en in de juiste volgorde een serie handelingen verricht. Er zijn echter ook weer robots in een productielijn die wel AI gebruiken om een deeltaak te verrichten. Een postsorteerrobot moet bijvoorbeeld (handgeschreven) postcodes kunnen lezen. Lezen ofwel beeldherkenning is een taak die we indelen bij AI. Het wordt trouwens steeds meer regel dan uitzondering dat productierobots ook van beeldherkenning gebruik maken.
Data gestuurd
Wat maakt de intelligentie van AI nu anders dan de intelligentie in CAS systemen of andersoortige niet-AI systemen? Waarom maakt beeldherkenning een deel uit van AI en het exact oplossen van een complexe wiskundige vergelijking niet? Bekijk eerst de volgende indeling binnen de AI applicaties.
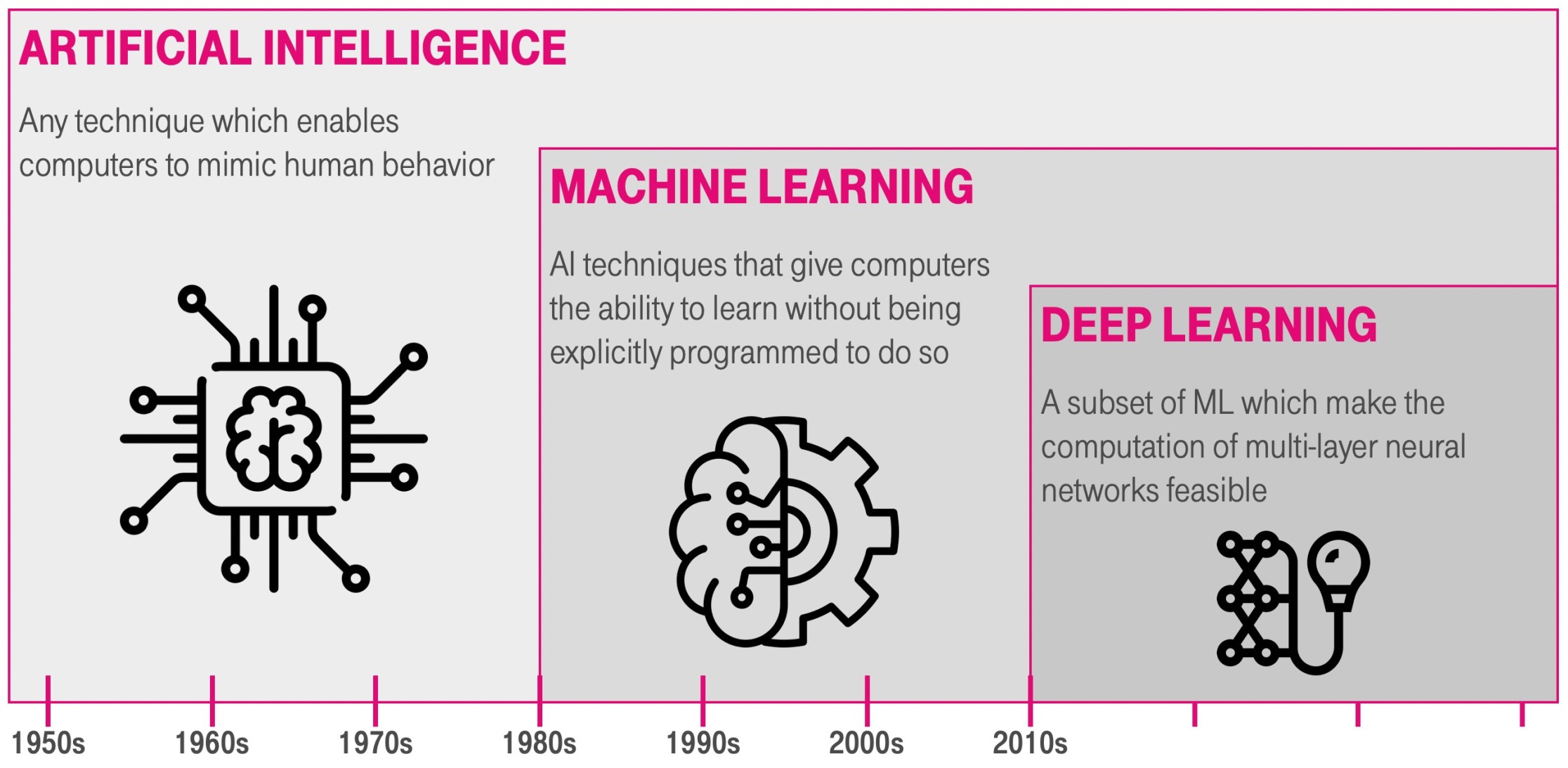
Machine en deep learning
Ingewikkelde neurale netwerken vallen onder "deep learning". Deze groep is bevat in de groep "machine learning" van lerende AI, die weer onderdeel uitmaakt van AI in zijn geheel. We beschouwen eerst het anders zijn van machine learning en deep learning ten opzichte van niet AI-systemen.
Het verschil tussen de "niet AI-systemen" en machine learning zit in de programmeerbaarheid van een directe oplossing. De wiskunde kent een grote maar eindige overzichtelijke verzameling van bekende functies en strategieën om een wiskundig probleem op te lossen. Een CAS systeem bevat al die functies en strategieën. Geef je zo'n systeem een probleem dan kan de precieze, van te voren geprogrammeerde, oplossingsstrategie worden opgezocht en uitgevoerd.
Je hebt in de introductie het Quickdraw spel gespeeld, een applicatie gebaseerd op AI. Het heeft je vast ook verbaasd dat jouw slechte tekening werd herkend. Ook in de Quickdraw applicatie moet worden gezocht naar een oplossing van een vraag. In dit geval: In welke categorie behoort die mooie tekening? Het is zeer onwaarschijnlijk dat jouw tekening precies terug kan worden gevonden in de database van tekeningen waarop Quickdraw is gebaseerd. Sterker nog, het is zowat onmogelijk dat jouw tekening beeldpunt voor beeldpunt overeenkomt met een andere tekening.
Er is dus wel een algoritme dat direct onderzoekt tot welke categorie jouw tekening behoort. Het stuurt jouw data door een recept (algoritme) ongeveer net zo als het CAS systeem dat doet. Maarrrrrr....., het recept dat jouw vragen beantwoordt is niet van te voren in de applicatie geprogrammeerd maar tot stand gekomen met behulp van een algoritme dat door middel van training die dit recept filtert uit data. De mogelijkheid tot aanpassen van een applicatie aan data noemt men het adaptieve vermogen. AI toepassingen hebben alle een adaptief vermogen. De data vormt de invoer van het trainingsproces. Een AI applicatie is dus data-gestuurd. Het trainingsalgoritme is natuurlijk wel van te voren geprogrammeerd.
De Quickdraw app heeft dus een algoritme dat tot stand is gekomen door training, dit algoritme is niet het algoritme van het leerproces maar is het resultaat van de training. De Quickdraw app wordt dan een agent (vertegenwoordiger) genoemd van het geleerde.
Bij training is het noodzakelijk dat er een input-output relatie is, ofwel de data moet op de een of andere manier worden gekoppeld aan de oplossing. Je zult straks zien dat bij winkelmandjes analyse (associatie analyse) en clustering deze koppeling vast ligt in het trainingsalgoritme. Alleen de data zorgt dan voor de variatie in het recept. Het verkregen recept of wel het algoritme van de agent wordt een statistisch resultaat.
Bij deep learning en eenvoudigere neurale netwerken (b.v. postcode herkennen), is ook de input-output relatie niet bekend. Bij deze vorm van AI wordt verwacht dat de training plaats vindt met input en bijbehorende output. Echter het is niet bekend hoe de relatie tussen die input en die output is. Het trainingsalgoritme heeft dan de taak de input-output relatie te schatten. Het algoritme geeft geen zekerheid over de gevonden relatie. De gevonden input-output relatie, die wordt gebruikt in de agent, is nu zelf ook een statistisch resultaat. In figuur 2 is dit weergegeven. Een applicatie die geen AI is en die eventueel gebruikt maakt van data verwerkt de invoer direct tot een uitvoer. De agents in de rechter twee diagrammen berekenen ook direct de uitvoer bij een invoer, maar kunnen dit pas nadat het algoritme in de agent door training is gemaakt.


We geven een simpel voorbeeld van een onderscheid tussen een rechttoe rechtaan berekening en één die gebaseerd is op een statistisch resultaat. Neem jouw eindrapportcijfer voor informatica. Dit cijfer is een gemiddelde van behaalde cijfers. Haal jij gemiddeld lager dan een 5,5 dan wordt jij bij de leerlingen met een onvoldoende ingedeeld. De grens 5,5 is door de school vast gekozen. Het recept is een simpele wiskundige berekening: vergelijk het cijfer met 5,5.
Nu bekijken we jouw resultaat voor het wiskunde op het eindexamen. Je docent kijkt dan jouw werk na en geeft het puntentotaal door aan het College voor Examens (CVE). Het CVE krijgt de cijfers binnen van alle leerlingen die een examentoets (bijvoorbeeld wiskunde) maken, maar gebruikt slechts een deel van die cijfers voor het bepalen van de **N-term** voor dit examen. De N-term is één getal, behorend bij het examen van één vak, waarmee jouw puntenaantal wordt omgezet in een cijfer voor het examen. Leerlingen en docenten zitten na afloop van de examens in spanning af te wachten wat de N-termen voor de vakken dit examenjaar weer zullen zijn. **Deze N-termen zijn op data gebaseerd en daarom een statistisch resultaat**. Je kunt het gebruik van de N-term in het bepalen van het eindcijfer nu beschouwen als een statistisch recept (b.v. vwo 2-de tijdvak 2021, havo 1-ste tijdvak).
Het voorbeeld van het examencijfer voor wiskunde is nog te simpel om er AI voor in te zetten. Er hoeft maar één getal te worden bepaald op basis van data die ook slechts uit de score van de leerlingen bestaat. Het algoritme om de N-term te bepalen is daarom relatief eenvoudig. Het wordt pas nuttig om AI in te zetten als het recept of de data complex is. Deze complexiteit is er vaak al snel. Hoe kan een auto zelf rijden? Hoe herkent een postsorteerrobot een bijvoorbeeld een postcode? Hoe krijg je al die aanvullingen bij je zoekopdrachten in Google? Hoe kan ik een verzameling cd's zo goed mogelijk in groepen indelen? Hoe kan Quickdraw herkennen wat je getekend hebt? Op dit laatste voorbeeld gaan we verder in.
Het Quickdraw voorbeeld is vergelijkbaar met het postcode lezen door de robot. Voordat Quickdraw jouw plaatje kan classificeren moet er dus een classificeringsrecept worden gemaakt. Dit classificeringsrecept moet worden gemaakt op basis van voorbeeldtekeningen. Eén tekening is wel maar één datapunt, maar dit datapunt is complex. Het bestaat uit heel veel beeldpunten, namelijk de grootte van het canvas. Al die beeldpunten moeten worden meegenomen, waardoor het datapunt dus niet maar één getal is, zoals bij het N-term voorbeeld hierboven.
Om het nog lastiger te maken zijn de beeldpunten niet onafhankelijk van elkaar, een lijnstuk is een verzameling van punten. Deze relatie moet door de AI applicatie worden ontdekt. Ieder van die beeldpunten krijgt invloed door daar een getal (parameter) aan te koppelen. Net als bij de bepaling van de N-term moeten al deze parameters worden geschat. Dit gaat helaas niet in één keer. Er wordt een set parameters gekozen, dan wordt er gekeken of de output behorende bij de trainingsdata door het nieuwe recept goed worden voorspeld. Zo nee dan worden de parameters in het recept weer aangepast enz. Het trainen van AI is in het algemeen een algoritme waarin herhaling (recursie) aanwezig is.
Niet lerende AI
In de bovenstaande sectie hebben we het verschil tussen een applicatie die geen AI bevat en lerende AI bekeken. Er is ook AI die niet leert. Voorbeelden voor het gebruik van AI zonder ML zijn op regels gebaseerde systemen zoals de eerste chatbots (b.v. Eliza, Parry, Jabberwacky ). Door de mens gedefinieerde regels laten de chatbot vragen beantwoorden en - in beperkte mate - klanten helpen . Er is geen machine learning nodig en de chatbot krijgt zijn intelligentie alleen door een grote hoeveelheid kennis door menselijke inbreng. In 1985 kreeg dit type AI zelfs een naam: “Good Old-Fashioned Artificial Intelligence” (GOFAI). Een ander voorbeeld is natuurlijke taalverwerking (NLP), waarbij de kennis van experts met betrekking tot grammatica en de betekenis van woorden van menselijke taal wordt gecodeerd in computermodellen en methoden om taal te interpreteren en te produceren. De GOFAI bevat dus een grote hoeveelheid kennis, die moeilijk te volgen is door een enkele persoon en vaak de kennis van een enkele persoon overtreft. Deze kennis vormt de data van de applicatie en juist door de ingewikkeldheid van die data heeft men dit soort applicaties AI genoemd.
Kenmerken voor AI-toepassingen
Na de koppeling tussen AI en data te hebben gelegd geven we hier een aantal argumenten om AI in te zetten.
- Je kunt geen direct algoritme schrijven voor het vraagstuk.
- Bij het examencijfer voorbeeld kan de statistische N-Term met een relatief eenvoudig direct algoritme worden bepaald. Als de data complex is dan lukt dat vaak niet en wordt het vinden van het beste statistische algoritme complex.
- De invoer die het programma krijgt, is niet volledig te bepalen en is complex .
- De invoer is bepalend voor de uitkomst van het algoritme. Als niet alle mogelijke invoer beschikbaar is (b.v. alle mogelijke schetsen van een kat) en bovendien de input niet zo simpel is dat er een direct algoritme kan worden gemaakt dan kan AI worden ingezet.
- De oplossingsstrategie is niet bekend.
- Met behulp van kunstmatige intelligentie is het vaak mogelijk een oplossingsstrategie te vinden. Deze oplossingsstrategie is dan niet verklarend, maar werkt wel.
In de volgende secties behandelen we Machine Learning (ML). We beginnen met een algemeen deel machine learning waarin we het leerproces algemeen beschouwen. Daarna ga je leren wat de algoritmen van de meest verklaarbare ML technieken associatie analyse en cluster analyse. Vervolgens behandelen we de minder verklaarbare resultaten van neurale netwerken gebruikt in deep learning (DL) en als laatste de inzet van deze technieken in multi-agent systemen.
- Leg uit wat het verschil is tussen het algoritme dat het probleem beantwoordt bij een applicatie die op AI is gebaseerd en een applicatie die dat niet is.
antwoord
- Bij een op AI gebaseerde applicatie is het algoritme dat het probleem beantwoordt een een statistisch resultaat na training met data. Het algoritme dat het probleem beantwoordt in het andere geval is een bedacht algoritme dat het probleem direct oplost.
- Wanneer is voor een probleemstelling kunstmatige intelligentie te gebruiken? Welke kenmerken ken je?
antwoord
- In de theorie worden 3 kenmerken genoemd:
- Je kunt geen direct algoritme te schrijven voor het vraagstuk.
- De invoer die het programma krijgt, is niet volledig te bepalen en is complex.
- De oplossingsstrategie is niet bekend.
- In de theorie worden 3 kenmerken genoemd:
- Geef een voorbeeld van een vraagstuk waar kunstmatige intelligentie toe te passen is. Geef ook aan waarom dit zo is.
antwoord
- ...
- Geef van de volgende toepassingen aan welke van de 3 kenmerken de grootste rol speelt en verklaar waarom.
- Suggesties voor andere producten in een webwinkel
- Het herkennen van postcodes
- Het indelen in groepjes van vergelijkbare films.
antwoord-
- De invoer die het programma krijgt, is niet volledig te bepalen en is complex. Er is een algoritme voor dit probleem. Echter, de aankopen van andere klanten bepalen welke suggesties je krijgt.
- De oplossingsstrategie is niet bekend. Hoewel het voor ons brein heel eenvoudig is om cijfers en letters te herkennen, is het niet mogelijk om uit te leggen hoe je dat precies aanpakt. Een direct algoritme kan niet worden geschreven.
- De invoer die het programma krijgt, is niet volledig te bepalen en is complex. Je kunt een aantal kenmerken aan een film koppelen en daar de film op laten indelen. Echter de hele verdeling van de eigenschappen over de films is niet bekend. De AI groepeert dan op de meeste overeenkomsten in de kenmerken.
- Geef de termen waarvan AI, DL, ML de afkortingen zijn en zet die in de volgende zin.
... is een onderdeel van ... dat weer onderdeel is van ...antwoord- Deep learning is een onderdeel van machine learning dat weer een onderdeel is van artificiële intelligentie.
- Noem een techniek die onder kunstmatige intelligentie valt maar niet onder machine learning.
antwoord
- De oudere chatbots of natuurlijke taalverwerking.
- Leg uit wat adaptief vermogen van een applicatie is.
antwoord
- Het adaptief vermogen van een applicatie is dat de werking van een applicatie door het aanbieden van trainingsdata kan veranderen.
- Verdedig de uitspraak "Het aanscherpen van de Corona maatregelen is gebaseerd op een statistisch resultaat".
antwoord
- Het RIVM houdt bij hoeveel besmettingen er per dag zijn, hoeveel personen er in de ziekenhuizen belanden. De test, om vast te stellen of iemand besmet is, is niet 100% betrouwbaar. Bovendien laat niet iedereen zich testen. Er zijn dus onzekerheden in de data die ervoor zorgen dat de afgeleide informatie statistisch is. Op basis van deze informatie worden besluiten genomen.
- Verdedig de uitspraak "Het aanscherpen van de Corona maatregelen is gebaseerd op een vaste regel".
antwoord
- De rijksoverheid heeft een routekaart voor het reageren op Covid-19 gemaakt waarin verschillende risiconiveaus zijn aangegeven. De grenzen, om van het ene risiconiveau naar het andere over te gaan, zijn door de overheid vastgesteld en lijken vooralsnog onafhankelijk van de virusvariant die er heerst. Hoewel er statistische variatie is in de data zijn de grenzen onveranderlijk gesteld. De grens is vooralsnog niet adaptief.