Toepassingen in Big Data kunnen, zoals we al hebben gezien het hoofdstuk Trends in deze AI cursus en de hoofdstukken Big Data en De kosten van Gratis uit de overkoepelende cursus Informatie, nuttig zijn maar ook een bedreiging vormen voor het individu. Maar hoe wordt de informatie geleverd door dit soort toepassingen verkregen uit de data?
De meeste van deze toepassingen gebruiken Artificiële Intelligentie om b.v. patronen te herkennen of groeperingen te maken, technieken die we zijn tegen gekomen in het hoofdstuk Technieken. In dit deel van de cursus gaan we een paar van die wiskundige technieken verder uitwerken. Ben jij een leerling die geïnteresseerd is in wiskunde en de toepassingen van wiskunde voel je dan uitgedaagd. De berekeningen in dit hoofdstuk zijn echter niet ingewikkeld en zijn voor iedere leerling op havo en vwo makkelijk uit te voeren.
Na dit hoofdstuk:
Bij associatieanalyse is het de bedoeling dat we een gegeven set kenmerken (bijvoorbeeld jouw leeftijd, geslacht, ingetypte zoekopdracht, beluisterde muziek) kunnen koppelen aan een andere set kenmerken (bijvoorbeeld reclame passend bij doelgroep omschrijving, leeftijd en geslacht ). Het resultaat van de associatie is dan de uitvoer van de toepassing (bijvoorbeeld de reclame die in de zoekmachine verschijnt, muziek die jij ook wel leuk zou vinden).
De wiskundige techniek gebruikt in associatieanalyse is de verzamelingenleer. Laten we eens kijken wat de verzamelingenleer inhoud.
| Symbolen | |
|---|---|
| Notatie | Betekenis |
| $\in$ | ’is een element van’, ’behoort tot’ |
| $\subset$ | ’is een deelverzameling van’ |
| {,} | accolades worden gebruikt om een verzameling aan te duiden |
| $\cap$ | ’doorsnede’, het gemeenschappelijke deel van de twee verzamelingen |
| $\cup$ | ’vereniging’, de elementen van de eerste en tweede verzameling worden samengenomen |
| $\#$ | ’aantal’, $\# A$ is het aantal elementen in $A$. |
| $\Rightarrow$ | ’implicatie’, al links waar is dan is ook rechts waar. |
In plaats van een ‘groep’ spreken we van een verzameling ($V$) (set).
In een verzameling bevindt zich individuen, beter bekent als elementen
$$V=\{v_{1},v_{2},v_{3},\cdots ,v_{n}\}.$$
Een verzameling representeert een aantal elementen met een bepaalde gezamenlijke eigenschap ($x$),
zoals de eigenschap ‘mens’ of ‘plezierig’.
Een verzameling bestaat uit elementen, en als $x$
een element van een verzameling $X$ noteren we dit als $x \in X$.
We gebruiken accolades { en } om verzamelingen te noteren.
We gebruiken binnen de accolades het symbool | om elementen met bepaalde eigenschappen aan te geven,
zoals in $\{x \in \mathbb{N} | x \, is\, deelbaar \, door \, 2 \}$
Zo is bijvoorbeeld $\{Melk , Brood , Kaas\}$ de verzameling met de elementen melk, brood, en kaas en
$Melk \in \{Melk , Brood , Kaas\}$, melk is een element van deze verzameling.
Relaties tussen verzamelingen |
|
|
$X \subset Y$
|
Als voor twee verzamelingen $X$ en $Y$ geldt dat elk element van $X$ ook een element is van $Y$, dan zeggen we dat $X$ een deelverzameling (subset) is van $Y$. Notatie: $X \subset Y = \{ \forall x: x \in X \rightarrow x \in Y \} $ Zo is bijvoorbeeld $X=\{Melk , Kaas\}$ een deelverzameling van $Y = \{Melk , Brood , Kaas\}$ |
|
$X \cap Y$
|
De doorsnede (intersection) $X \cap Y$ van twee verzamelingen $X$ en $Y$ bestaat uit de gemeenschappelijke elementen van $X$ en $Y$. $X \cap Y = \{ x| x \in X \, \wedge \, x \in Y \}$
Zo is bijvoorbeeld $\{Melk , Brood , Kaas\} \cap \{Melk , Brood , Pindakaas\}$
de verzameling met de elementen $Melk$ en $Brood$. |
|
$X \cup Y$
|
De vereniging (union) $X \cup Y$ van twee verzamelingen $X$ en $Y$ bestaat uit de elementen die tot $X$, tot $Y$ of tot beide horen. $X \cup Y = \{ x| x \in X \, \vee \, x \in Y \}$. Zo is bijvoorbeeld $\{Melk , Brood , Kaas\}\cup\{Melk , Brood , Pindakaas\}$ de verzameling met de elementen $Kaas, Melk, Brood$ en $Pindakaas$. $\{Melk , Brood , Kaas\}\cup\{Melk , Brood , Pindakaas\} = \{Kaas, Melk, Brood, Pindakaas\}$ |
Voor eindige verzamelingen $A$ definieren we $\#(A)$ als het aantal elementen in $A$. Zo is bijvoorbeeld $\#({Chips,Zeep,Appels})=3$.
Een element van een verzameling kan zelf ook een verzameling zijn. Zo bestaat de verzameling $C= \{ \{ Chips,Zeep,Appels \}, \{Chips,Zeep,Appels\}, \{Zeep,Bananen\},\{Chips,Zeep,Bananen\}\}$ uit vier elementen.
Binnen de verzamelingenleer definiëert men een dergelijke verzameling waarvan de elementen ook
weer verzamelingen zijn als een collectie.
Nog voorbeeld is de collectie:
$$D=\{\{banaan\},\{chips\},\{melk\},\{pruim\},\{banaan,rum\},\{chips,rum\},\{banaan,chips,melk\},
\{banaan,rum,melk,pruim\}\}$$
De collectie $D$ bestaat dus uit de verzamelingen:
$T1=\{banaan\}$,
$T2=\{chips\}$,
$T3=\{melk\}$,
$T4=\{pruim\}$,
$T5=\{banaan,rum\}$,
$T6=\{chips,rum\}$,
$T7=\{banaan,chips,melk\}$ en
$T8=\{banaan,rum,melk,pruim\}$
Om uitspraken te kunnen doen over verbanden tussen verzamelingen en de waarde van die verzamelingen zijn de volgende definities van belang:
De associatieregel $X \Rightarrow Y $ betekent: als de deelverzameling $X$ voorkomt dan komt ook de deelverzameling $Y$ voor.
De support van een deelverzameling $X$ is het aantal
deelverzamelingen van een collectie $C$ waar de elementen van $X$ in voorkomen gedeeld
door het aantal elementen van deze collectie.
Notatie: $support(X)=\frac{frq(X)}{\#(C)}$
Waarbij $freq(X)$ het aantal deelverzamelingen is waarin de elementen van $X$
voorkomen.
Voor de bovenstaande collectie $D$ geldt:
Een praktische toepassing: Bij marktonderzoek is de support van een stel artikelen (b.v. $K=\{televisie,surround set\}$) het aantal klanten dat al die artikelen koopt, meestal als percentage van het totaal aantal klanten.
Een stel artikelen $K$ met hoge support (boven een zekere drempel) heet frequent (Ofwel ten opzichte van het totaal aantal klanten kopen veel klanten alle artiklen in $K$).
Een itemset is een deelverzameling van elementen van een stel artikelen. Een $k$-itemset is een deelverzameling die $k$ elementen bevatten.
Er moet voldoende vertrouwen zijn in de associatieregel. Om dit te kunnen bepalen, berekent men de confidence van de associatieregel.
De confidence van $X \Rightarrow Y$ is per definitie de support van de
vereniging van $X$ en $Y$ gedeeld door de support van $X$.
In notatievorm: $confidence(X \Rightarrow Y) = \frac{support(X \cup Y)}{support(X)}$
Omdat $\frac{support(X \cup Y)}{support(X)}=\frac{frq(X \cup Y)}{frq(X)}$, geldt ook:
$confidence(X \Rightarrow Y) =\frac{frq(X \cup Y)}{frq(X)}$
Bij marktonderzoek is de confidence een maat voor de kans dat iemand $Y$ koopt, gegeven dat hij $X$ ook in zijn boodschappenmandje heeft.
| Collectie $I$ | |
|---|---|
| Id | Items |
| 0 | $\{Pasta,Kaas,Tomaat\}$ |
| 1 | $\{Pasta,Room\}$ |
| 2 | $\{Pasta,Tomaat\}$ |
| 3 | $\{Kaas,Room\}$ |
| 4 | $\{Kaas,Tomaat\}$ |
| 5 | $\{Pasta,Tomaat,Room\}$ |
| 6 | $\{Tomaat,Room\}$ |
| 7 | $\{Kaas,Tomaat\}$ |
| 8 | $\{Pasta,Kaas,Tomaat,Room\}$ |
| 9 | $\{Pasta\}$ |
Er bestaan veel algoritmes om associatieregels te ontdekken. De oudste en meest bekende methode is het Apriori principe
(a priori : op basis van eerder onderzoek) ontwikkeld voor transacties (verkopen). Het is in de jaren negentig bedacht door Agrawal en anderen. Gegeven een drempelwaarde $C$ identificeert het algoritme alle itemsets (deelverzamelingen) in de gehele dataset die minstens $C$ transacties in de database bevatten.
Apriori gebruikt een "bottom up" aanpak. Veel voorkomende subsets worden item voor item uitgebreidt (een stap genoemd kandidaat generatie ), waarna de groepen van kandidaten worden getoetst tegen de gehele dataset. Het algoritme stopt als er geen succesvolle uitbreiding gevonden kan worden. Het is gebaseerd op de volgende observatie. Iedere deelverzameling van een frequente itemset (veel voorkomende itemset) is zelf ook weer een frequente itemset.
Deze fasen worden per niveau uitgevoerd, dus voor verzamelingen of items met grootte 1, met grootte 2, enzovoort.
Het algoritme stopt wanneer er geen kandidaten meer gevonden kunnen worden.
De flowchart hiernaast geeft de grafische weergave van het algoritme. Hieronder behandelen we de stappen aan de hand van een voorbeeld.
| Collectie $W$ | |
|---|---|
| Id | Items |
| 0 | $\{Spaghetti, Tomatensaus\}$ |
| 1 | $\{Spaghetti, Brood\}$ |
| 2 | $\{Spaghetti, Tomatensaus, Brood \}$ |
| 3 | $\{Brood,Boter\}$ |
| 4 | $\{Brood, Tomatensaus\}$ |
Stel je hebt als winkel een groot aantal verkopen per klant, (Collectie $W$)
Vraag: Genereer de grootste k-itemsets met behulp van het Apriori-algoritme. Zorg voor een minimale support van 40%.
Iteratie met k=1
| Itemset | Support |
|---|---|
| $\{Spaghetti\}$ | 60% |
| $\{Tomatensaus\}$ | 60% |
| $\{Brood \}$ | 80% |
| $\{Boter\}$ | 20% |
Iteratie met k=2
| Itemset | Support |
|---|---|
| $\{Spaghetti, Tomatensaus \}$ | 40% |
| $\{Spaghetti, Brood \}$ | 40% |
| $\{Tomatensaus, Brood \}$ | 40% |
Iteratie met k=3
| Itemset | Support |
|---|---|
| $\{Spaghetti,Tomatensaus, Brood\}$ | 20% |
Na het einde bestaat de uiteindelijke set van voldoende frequente verzamelingen uit
$F=\{\{Spaghetti\}, \{Tomatensaus\}, \{Brood\}, \{Spaghetti,Tomatensaus\}, \{Spaghetti, Brood \}, \{Tomatensaus, Brood \}\}$.
Hieruit kunnen we onderstaande associatie regels afleiden. De eerste regel zegt bijvoorbeeld dat in 67% van de gevallen dat een klant spaghetti koopt, koopt deze ook brood.
| Associatieregels | Confidence |
|---|---|
| $\{Spaghetti\} \Rightarrow \{Spaghetti,Tomatensaus\}$ | $\frac{40}{60}= 67 \% $ |
| $\{Spaghetti\} \Rightarrow \{Spaghetti,Brood\}$ | $\frac{40}{60}= 67\% $ |
| $\{Brood\} \Rightarrow \{Spaghetti,Brood\}$ | $\frac{40}{60}= 67\% $ |
| $\{Brood\} \Rightarrow \{Spaghetti,Brood\}$ | $\frac{40}{80}= 50\% $ |
| $\{Brood\} \Rightarrow \{Tomatensaus,Brood\}$ | $\frac{40}{80}= 50\% $ |
| $\{Tomatensaus\} \Rightarrow \{Tomatensaus,Brood\}$ | $\frac{40}{60}= 67\% $ |
| $\{Spaghetti\} \Rightarrow \{Tomatensaus,Spaghetti\}$ | $\frac{40}{60}= 67\% $ |
| Collectie $W$ | |
|---|---|
| Id | Items |
| 0 | $\{a,b,c\}$ |
| 1 | $\{b,c,d,e\}$ |
| 2 | $\{c,d \}$ |
| 3 | $\{a,b,d\}$ |
| 4 | $\{a,b,c\}$ |
| Itemset | Support |
|---|---|
| $\{a\}$ | 60% |
| $\{b\}$ | 80% |
| $\{c \}$ | 80% |
| $\{d\}$ | 60% |
| $\{e\}$ | 20% |
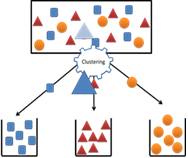
Clusteranalyse is het classificeren of het groeperen in 'clusters' of
'klassen' van objecten op grond van hun kenmerken. Het doel van
clusteranalyse is het vormen van deelverzamelingen die elk hun eigen
gedeelde kenmerken bevatten.
Het doel van clusteranalyse is het verdelen van een dataset in groepen.
Deze groepen en het aantal groepen zijn vooraf niet bekend. Het
streven is zoveel mogelijk gelijkenis binnen een groep en zoveel
mogelijk verschil tussen de groepen te krijgen. In tegenstelling tot
classificatie: daar weten we de indeling in groepen al, en willen we een
nieuw object in de juiste groep krijgen. Clusteranalyse is vooral bekend
uit marktonderzoek en wordt veel ingezet om het koopgedrag van
klanten te onderzoeken. Het doel van de analyse is niet het voorspellen
van dit koopgedrag, maar het zoeken naar een beperkt aantal groepen
klanten met hetzelfde koopgedrag. Online kan deze techniek heel goed
worden ingezet om websitebezoek te onderzoeken. Hiermee kunnen
verschillende doelgroepen op een effectieve wijze benaderd worden.
Een bedrijf krijgt zo zicht op welk product of dienst een groep klanten
het beste aansluit, en welke product eventueel niet haalbaar of minder
bereikbaar zijn voor de klantengroep.
In de biologie zijn er meerdere gebieden waar clusteranalyse wordt
toegepast. Denk bijvoorbeeld aan de classificatie van verschillende
organismen. Elk organisme hoort bij een soort. Soorten kunnen op hun
beurt weer worden onderverdeeld in lagere taxa, zoals ondersoort en
variëteit. Soorten zelf worden samengevoegd in geslachten en deze
weer in families en in taxa van nog hogere rang. Een ander voorbeeld
van het gebruiken clustertechnieken in de biologie is het maken van
groepen met genen die zie een bepaalde erfelijke ziekte kunnen
bevatten. Door het gebruik van clustermethodes kunnen de groepen
met genen gevonden worden. Als deze groepen bekend zijn, wordt het
gemakkelijk een medicijn te ontwikkelen dat de erfelijke ziekte kan
voorkomen of genezen.
Afstand tussen twee punten
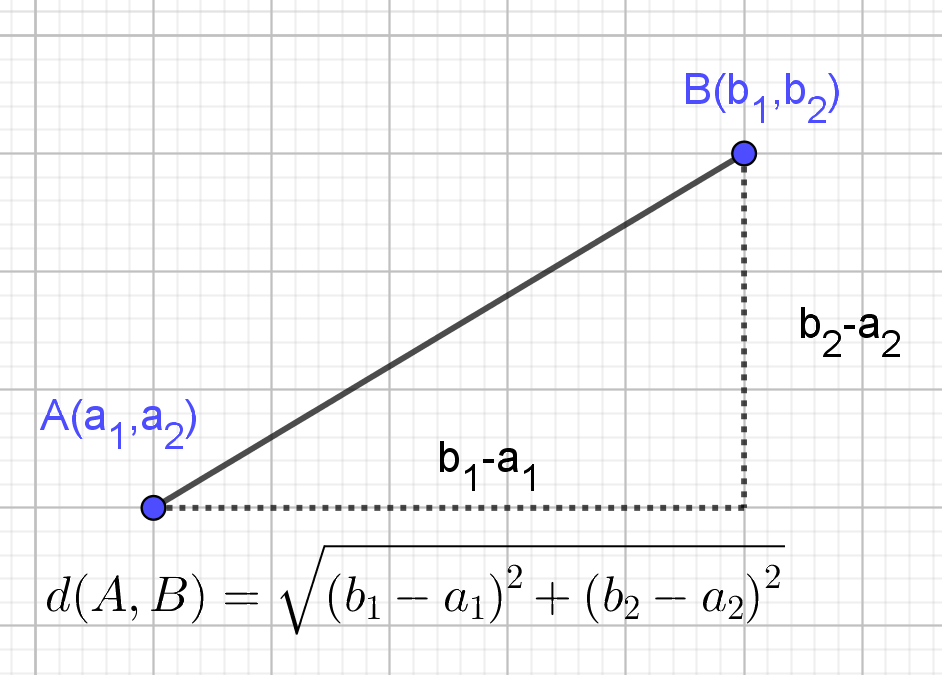
In de wiskunde kan de afstand worden berekend als de wortel uit de
som van de kwadraten van de verschillen tussen de coördinaten,
volgens de stelling van Pythagoras, zie Figuur 3.5.2. Deze
afstand noemen we de Euclidische astand. In drie dimensies
en hoger wordt deze op een zelfde manier berekend.
Dit is een maat die aangeeft hoe groot de ‘overeenkomst’ of het
‘verschil’ is tussen twee kenmerk datapunten.
Er zijn twee bekende methoden om de afstand tussen waarnemingen:
| Object $A$ | 10 | 12 | 15 | 13 | 9 |
| Object $B$ | 18 | 23 | 13 | 15 | 17 |
De Manhattan of City-block afstand is: $d(A,B)= |10−8|+|12−23|+|15−13|+|13−15|+|9−17|=25$
De Euclidische afstand is: $d(A,B)=\sqrt{(10−18)^{2}+(12−23)^{2}+(15−13)^{2}+(13−15)^{2}+(9−17)^{2}} =16,16$
Een matrix van afstanden is een matrix waarvan de elementen de afstanden tussen de punten aangeven.
Twee dimensionale Euclidische afstand $d(A,B)=\sqrt{(a_{1}-b_{1})^{2}+ (a_{2}-b_{2})^{2}}$
Voorbeeld B
| x | y | |
|---|---|---|
| A | 2 | 1 |
| B | 4 | 2 |
| C | 6 | 1 |
| D | 7 | 2 |
| A | B | C | D | |
|---|---|---|---|---|
| A | 0 | 2.24 | 4 | 5.1 |
| B | 2.24 | 0 | 2.24 | 3 |
| C | 4 | 2.24 | 0 | 1.41 |
| D | 5.1 | 3 | 1.41 | 0 |
Als je de afstand tussen elk paar van objecten weet, wat is dan de
afstand tussen twee clusters $C_{1}$ en $C_{2}$?
We nemen hier de kleinste afstand tussen twee objecten waarvan er één
in $C_{1}$ aanwezig is en de andere in $C_{2}$. Deze afstand noemt men
Single Linkage.
Single Linkage: $d(C_{1},C_{2})=\min\{d(A,B)|A \in C_{1}\,\,en\,\, B \in C_{2} \}$
Voorbeeld C
| x | y | |
|---|---|---|
| $A_{1}$ | 1 | 3 |
| $A_{2}$ | 1 | 4 |
| $A_{3}$ | 2 | 2 |
| $B_{1}$ | 5 | 1 |
| $B_{2}$ | 5 | 2 |
| $B_{3}$ | 7 | 2 |
| $B_{1}$ | $B_{2}$ | $B_{3}$ | |
|---|---|---|---|
| $A_{1}$ | 4.47 | 4.12 | 6.03 |
| $A_{2}$ | 5 | 4.47 | 6.32 |
| $A_{3}$ | 3.16 | 3 | 5 |
Het centrum $M(m_{1},m_{2}, \dots, m_{n})$ van een cluster wordt bepaald als het gemiddelde van de coördinaten van de punten in de cluster. Wiskundig gezien is het het zwaartepunt van de veelhoek die door de punten wordt gevormd.
Centrum $M$ van een cluster:
$M(m_{1},m_{2}, \dots, m_{n})= \left( \frac{\sum^{1}_{n} a_{1i}}{n},\frac{\sum^{1}_{n} a_{2i}}{n}, \dots, \frac{\sum^{1}_{n} a_{ni}}{n}\right)$.
Voorbeeld D
| x | y | |
|---|---|---|
| $A_{1}$ | 0 | 0 |
| $A_{2}$ | 7 | 8 |
| $A_{3}$ | 4 | 8 |
| $A_{4}$ | 3 | 0 |
Er zijn twee methodes om tot clusters te komen: hiërarchische of partitiemethode. In deze paragraaf gaan we ons beperken tot niet-hiërarchisch clustering.
Niet-hiërarchisch of partitioneren betekent het stap voor stap verbeteren van een bestaande clustering.
Het oudste en meest bekende clusteralgoritme is de $K$-means methode. Later zijn er veel varianten ontwikkeld die gebaseerd zijn op deze methode. $K$-means is een eenvoudige, iteratieve manier van clusteren. Vooraf wordt bepaald hoeveel clusters je wilt hebben. Om de optimale verbetering van een bestaande clustering te vinden ga je als volgt te werk:
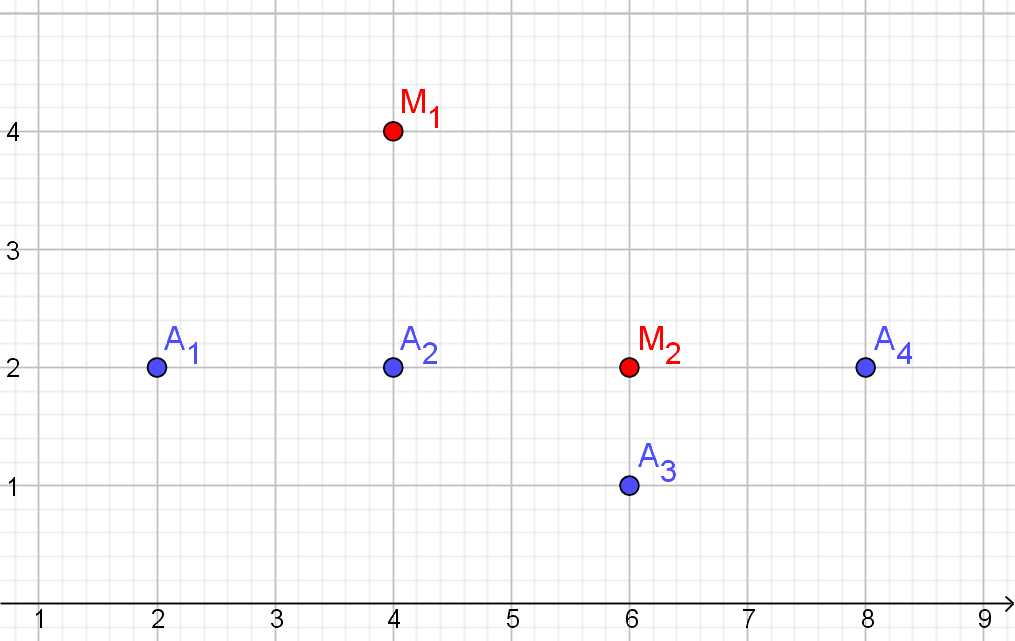
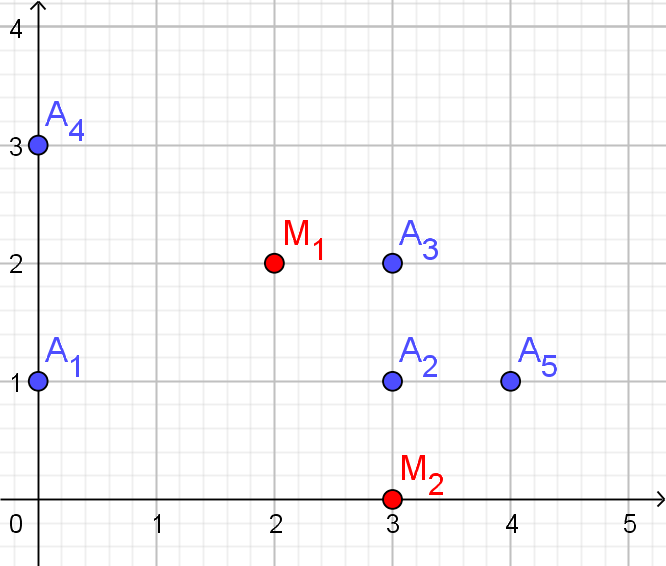
Start: Kies de centra van de clusters eerste keer gewoon willekeurig.Voorbeeld E
| x | y | |
|---|---|---|
| $A_{1}$ | 2 | 2 |
| $A_{2}$ | 4 | 2 |
| $A_{3}$ | 6 | 1 |
| $A_{4}$ | 8 | 2 |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 2.83 | 4 | $C_{1}$ |
| $A_{2}$ | 2 | 2 | $C_{1}$ |
| $A_{3}$ | 3.61 | 1 | $C_{2}$ |
| $A_{4}$ | 4.47 | 2 | $C_{2}$ |
| $C_{1}$ | $\{A_{1},A_{2}\}$ |
|---|---|
| $C_{2}$ | $\{A_{3},A_{4}\}$ |
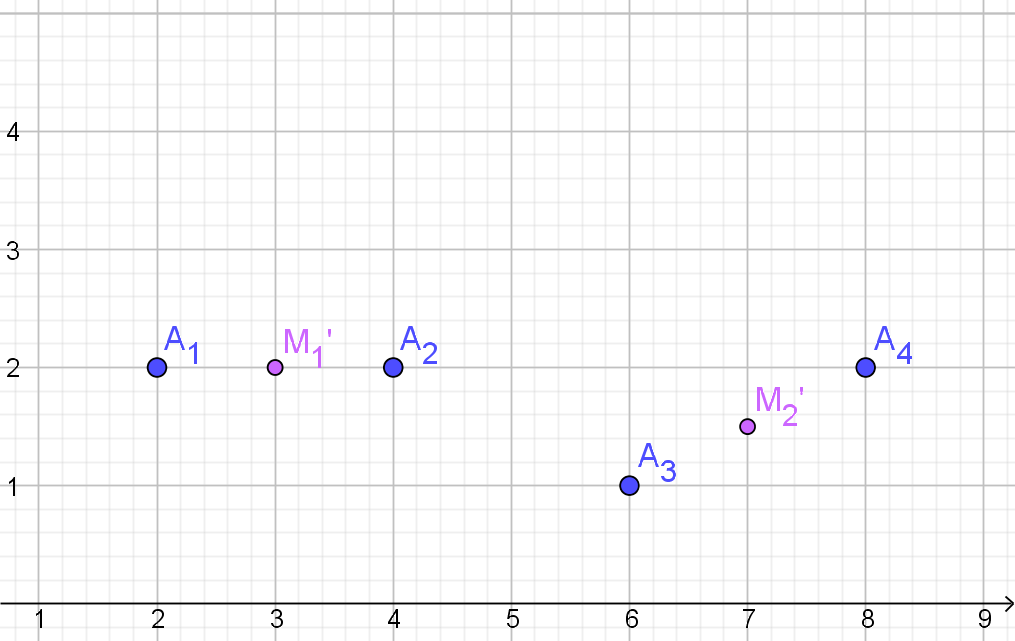
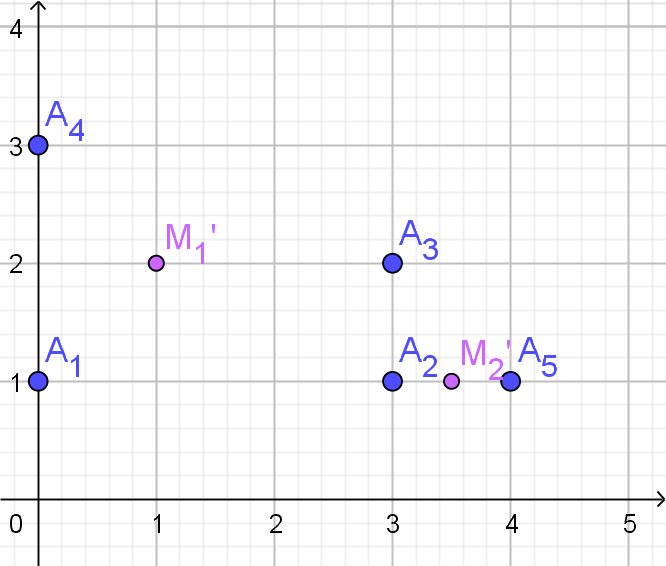
| $M_{1}'$ | $M_{2}'$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 1 | 5.02 | $C_{1}$ |
| $A_{2}$ | 1 | 3.04 | $C_{1}$ |
| $A_{3}$ | 3.16 | 1.12 | $C_{2}$ |
| $A_{4}$ | 4.47 | 1.12 | $C_{2}$ |
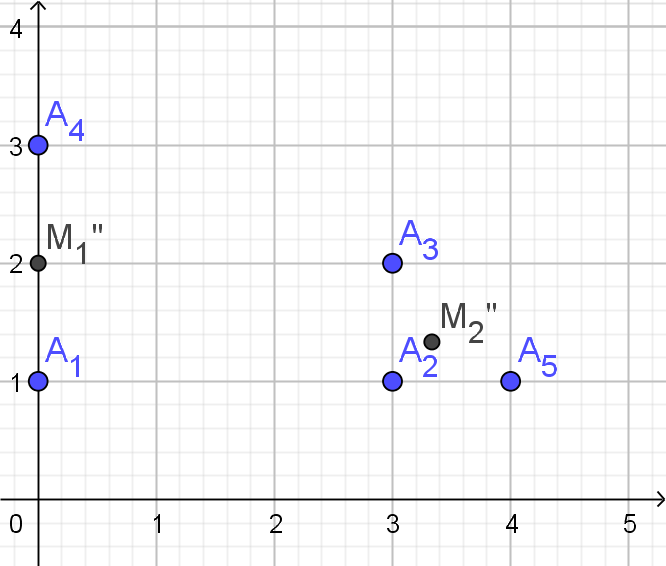
Voorbeeld F
| x | y | |
|---|---|---|
| $A_{1}$ | 0 | 1 |
| $A_{2}$ | 3 | 1 |
| $A_{3}$ | 3 | 2 |
| $A_{4}$ | 0 | 3 |
| $A_{5}$ | 4 | 1 |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 2.24 | 3.16 | $C_{1}$ |
| $A_{2}$ | 1.41 | 1 | $C_{2}$ |
| $A_{3}$ | 1 | 2 | $C_{1}$ |
| $A_{4}$ | 2.24 | 4.24 | $C_{1}$ |
| $A_{5}$ | 2.24 | 1.41 | $C_{2}$ |
| $C_{1}$ | $\{A_{1},A_{3},A_{4}\}$ |
|---|---|
| $C_{2}$ | $\{A_{2},A_{5}\}$ |
| $M_{1}'$ | $M_{2}'$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 1.41 | 3.5 | $C_{1}$ |
| $A_{2}$ | 2.24 | 0.5 | $C_{2}$ |
| $A_{3}$ | 2 | 1.12 | $C_{2}$ |
| $A_{4}$ | 1.41 | 4.03 | $C_{1}$ |
| $A_{5}$ | 3.16 | 0.5 | $C_{2}$ |
| $C_{1}$ | $\{A_{1},A_{4}\}$ |
|---|---|
| $C_{2}$ | $\{A_{2},A_{3},A_{5}\}$ |
| $x_{1}$ | $x_{2}$ | $x_{3}$ | $x_{4}$ | |
|---|---|---|---|---|
| $A_{1}$ | 6 | 3 | 4 | 5 |
| $A_{2}$ | 2 | 3 | 5 | 4 |
| $A_{3}$ | 5 | 4 | 6 | 3 |
| $A_{4}$ | 9 | 1 | 1 | 8 |
| $A_{5}$ | 8 | 2 | 0 | 9 |
| $A_{6}$ | 8 | 0 | 1 | 8 |
| $A_{4}$ | $A_{5}$ | $A_{6}$ | |
|---|---|---|---|
| $A_{1}$ | 5.57 | 6.08 | 5.57 |
| $A_{2}$ | 9.22 | 9.33 | 8.77 |
| $A_{3}$ | 8.66 | 9.22 | 8.66 |
| $A_{4}$ | $A_{5}$ | $A_{6}$ | |
|---|---|---|---|
| $A_{1}$ | |||
| $A_{2}$ | |||
| $A_{3}$ |
| $x_{1}$ | $x_{2}$ | |
|---|---|---|
| $O_{1}$ | 2 | 2 |
| $O_{2}$ | 8 | 6 |
| $O_{3}$ | 6 | 8 |
| $O_{4}$ | 2 | 4 |
| $O_{2}$ | $O_{4}$ | |
|---|---|---|
| $O_{1}$ | ||
| $O_{3}$ |
| $O_{2}$ | $O_{4}$ | |
|---|---|---|
| $O_{1}$ | 7.21 | 2 |
| $O_{3}$ | 2.83 | 5.7 |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $O_{1}$ | |||
| $O_{2}$ | |||
| $O_{3}$ | |||
| $O_{4}$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $O_{1}$ | 3.6 | 4.5 | $C_{1}$ |
| $O_{2}$ | 3.6 | 3.1 | $C_{2}$ |
| $O_{3}$ | 4.1 | 3.2 | $C_{2}$ |
| $O_{4}$ | 3 | 3.2 | $C_{1}$ |
| $M_{1}'$ | $M_{2}'$ | toewijzing | |
|---|---|---|---|
| $O_{1}$ | 1 | 7.1 | $C_{1}$ |
| $O_{2}$ | 6.7 | 1.4 | $C_{2}$ |
| $O_{3}$ | 6.4 | 1.4 | $C_{2}$ |
| $O_{4}$ | 1 | 5.8 | $C_{1}$ |
| $x_{1}$ | $x_{2}$ | |
|---|---|---|
| $D_{1}$ | 6 | 3 |
| $D_{2}$ | 2 | 3 |
| $D_{3}$ | 5 | 4 |
| $D_{4}$ | 9 | 1 |
| $D_{5}$ | 8 | 2 |
| $D_{6}$ | 8 | 0 |
| $M_{1}$ | $M_{2}$ | $M_{3}$ | toewijzing | |
|---|---|---|---|---|
| $D_{1}$ | ||||
| $D_{2}$ | ||||
| $D_{3}$ | ||||
| $D_{4}$ | ||||
| $D_{5}$ | ||||
| $D_{6}$ |
| $M_{1}$ | $M_{2}$ | $M_{3}$ | toewijzing | |
|---|---|---|---|---|
| $D_{1}$ | 2 | 1.1 | 2.83 | $C_{2}$ |
| $D_{2}$ | 2 | 5.0 | 6.3 | $C_{1}$ |
| $D_{3}$ | 1.4 | 2.5 | 4.2 | $C_{1}$ |
| $D_{4}$ | 5.4 | 2.5 | 1 | $C_{3}$ |
| $D_{5}$ | 4.1 | 1.1 | 1 | $C_{3}$ |
| $D_{6}$ | 5 | 2.7 | 1 | $C_{3}$ |
| $M_{1}'$ | $M_{2}'$ | $M_{3}'$ | toewijzing | |
|---|---|---|---|---|
| $D_{1}$ | 2.5 | 0 | 3 | $C_{2}$ |
| $D_{2}$ | 1.6 | 4 | 6.6 | $C_{1}$ |
| $D_{3}$ | 1.6 | 1.4 | 4.5 | $C_{2}$ |
| $D_{4}$ | 6 | 3.6 | 0.7 | $C_{3}$ |
| $D_{5}$ | 4.77 | 2.27 | 1.1 | $C_{3}$ |
| $D_{6}$ | 5.7 | 3.6 | 1.1 | $C_{3}$ |
| $x_{1}$ | $x_{2}$ | |
|---|---|---|
| $A_{1}$ | 0 | 0 |
| $A_{2}$ | 7 | 8 |
| $A_{3}$ | 4 | 8 |
| $A_{4}$ | 3 | 0 |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0,6)$ $M_{2}=(7,2)$ |
|
| Iteratie 1 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| Iteratie 2 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| ... |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 6.00 | 7.28 | $C_{1}$ |
| $A_{2}$ | 7.28 | 6.00 | $C_{2}$ |
| $A_{3}$ | 4.47 | 6.71 | $C_{1}$ |
| $A_{4}$ | 6.71 | 4.47 | $C_{2}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0,6)$ $M_{2}=(7,2)$ |
|
| Iteratie 1 | $C_{1}=\{A_{1},A_{3}\}$ $C_{2}=\{A_{2},A_{4}\}$ | $M_{1}=(2,4)$ $M_{2}=(5,4)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 4.47 | 6.40 | $C_{1}$ |
| $A_{2}$ | 6.40 | 4.47 | $C_{2}$ |
| $A_{3}$ | 4.47 | 4.12 | $C_{2}$ |
| $A_{4}$ | 4.12 | 4.47 | $C_{1}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0,6)$ $M_{2}=(7,2)$ |
|
| Iteratie 1 | $C_{1}=\{A_{1},A_{3}\}$ $C_{2}=\{A_{2},A_{4}\}$ | $M_{1}=(2,4)$ $M_{2}=(5,4)$ |
| Iteratie 2 | $C_{1}=\{A_{1},A_{4}\}$ $C_{2}=\{A_{2},A_{3}\}$ | $M_{1}=(1.5,0)$ $M_{2}=(5.5,8)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $A_{1}$ | 1.50 | 9.71 | $C_{1}$ |
| $A_{2}$ | 9.71 | 1.50 | $C_{2}$ |
| $A_{3}$ | 8.38 | 1.50 | $C_{2}$ |
| $A_{4}$ | 1.50 | 8.38 | $C_{1}$ |
| Leeftijd | Duur vakantie | |
|---|---|---|
| $TO_{1}$ | 19 | 3 |
| $TO_{2}$ | 25 | 8 |
| $TO_{3}$ | 43 | 14 |
| $TO_{4}$ | 61 | 14 |
| $TO_{5}$ | 30 | 7 |
| $TO_{6}$ | 22 | 10 |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(19,3)$ $M_{2}=(25,8)$ |
|
| Iteratie 1 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| Iteratie 2 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| ... |
| $TO_{1}$ | 0.00 | 7.81 | $C_{1}$ |
|---|---|---|---|
| $TO_{2}$ | 7.81 | 0.00 | $C_{2}$ |
| $TO_{3}$ | 26.40 | 18.97 | $C_{2}$ |
| $TO_{4}$ | 43.42 | 36.50 | $C_{2}$ |
| $TO_{5}$ | 11.70 | 5.10 | $C_{2}$ |
| $TO_{6}$ | 7.62 | 3.61 | $C_{2}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(19,3)$ $M_{2}=(25,8)$ |
|
| Iteratie 1 | $C_{1}=\{TO_{1}\}$ $C_{2}=\{TO_{2},TO_{3},TO_{4},TO_{5},TO_{6}\}$ | $M_{1}=(19,3)$ $M_{2}=(36.2,10.6)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $TO_{1}$ | 0.00 | 18.80 | $C_{1}$ |
| $TO_{2}$ | 7.81 | 11.50 | $C_{1}$ |
| $TO_{3}$ | 26.40 | 7.60 | $C_{2}$ |
| $TO_{4}$ | 43.42 | 25.03 | $C_{2}$ |
| $TO_{5}$ | 11.70 | 7.17 | $C_{2}$ |
| $TO_{6}$ | 7.62 | 14.21 | $C_{1}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0,6)$ $M_{2}=(7,2)$ |
|
| Iteratie 1 | $C_{1}=\{TO_{1}\}$ $C_{2}=\{TO_{2},TO_{3},TO_{4},TO_{5},TO_{6}\}$ | $M_{1}=(19,3)$ $M_{2}=(36.2,10.6)$ |
| Iteratie 2 | $C_{1}=\{TO_{1},TO_{2},TO_{6}\}$ $C_{2}=\{TO_{3},TO_{4},TO_{5}\}$ | $M_{1}=(1.5,0)$ $M_{2}=(5.5,8)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $TO_{1}$ | 5.00 | 27.09 | $C_{1}$ |
| $TO_{2}$ | 3.16 | 20.01 | $C_{1}$ |
| $TO_{3}$ | 22.14 | 2.87 | $C_{2}$ |
| $TO_{4}$ | 39.62 | 16.50 | $C_{2}$ |
| $TO_{5}$ | 8.00 | 15.39 | $C_{1}$ |
| $TO_{6}$ | 3.00 | 22.73 | $C_{1}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0,6)$ $M_{2}=(7,2)$ |
|
| Iteratie 1 | $C_{1}=\{TO_{1}\}$ $C_{2}=\{TO_{2},TO_{3},TO_{4},TO_{5},TO_{6}\}$ | $M_{1}=(19,3)$ $M_{2}=(36.2,10.6)$ |
| Iteratie 2 | $C_{1}=\{TO_{1},TO_{2},TO_{6}\}$ $C_{2}=\{TO_{3},TO_{4},TO_{5}\}$ | $M_{1}=(22,7)$ $M_{2}=(44.7,11.7)$ |
Iteratie 3 | $C_{1}=\{TO_{1},TO_{2},TO_{5},TO_{6}\}$ $C_{2}=\{TO_{3},TO_{4}\}$ | $M_{1}=(24,7)$ $M_{2}=(52,14)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $TO_{1}$ | 6.40 | 34.79 | $C_{1}$ |
| $TO_{2}$ | 1.41 | 27.66 | $C_{1}$ |
| $TO_{3}$ | 20.25 | 9.00 | $C_{2}$ |
| $TO_{4}$ | 37.66 | 9.00 | $C_{2}$ |
| $TO_{5}$ | 6.00 | 23.09 | $C_{1}$ |
| $TO_{6}$ | 3.61 | 30.27 | $C_{1}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0.6,1,0)$ $M_{2}=(7.2,1,0)$ |
|
| Iteratie 1 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| Iteratie 2 | $C_{1}=$ $C_{2}=$ | $M_{1}=$ $M_{2}=$ |
| ... |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $S_{1}$ | 1.54 | 7.34 | $C_{1}$ |
| $S_{2}$ | 7.34 | 1.54 | $C_{2}$ |
| $S_{3}$ | 4.43 | 2.79 | $C_{2}$ |
| $S_{4}$ | 2.79 | 4.43 | $C_{1}$ |
| Clusters | Centra | |
|---|---|---|
| Start | $M_{1}=(0.6,1,0)$ $M_{2}=(7.2,1,0)$ |
|
| Iteratie 1 | $C_{1}=\{S_{1},S{4}\}$ $C_{2}=\{S_{2},S{3}\}$ | $M_{1}=(1.5,0,1)$ $M_{2}=((6.3,2,1)$ |
| $M_{1}$ | $M_{2}$ | toewijzing | |
|---|---|---|---|
| $S_{1}$ | 1.50 | 6.61 | $C_{1}$ |
| $S_{2}$ | 6.61 | 1.50 | $C_{2}$ |
| $S_{3}$ | 3.86 | 1.50 | $C_{2}$ |
| $S_{4}$ | 1.50 | 3.86 | $C_{1}$ |