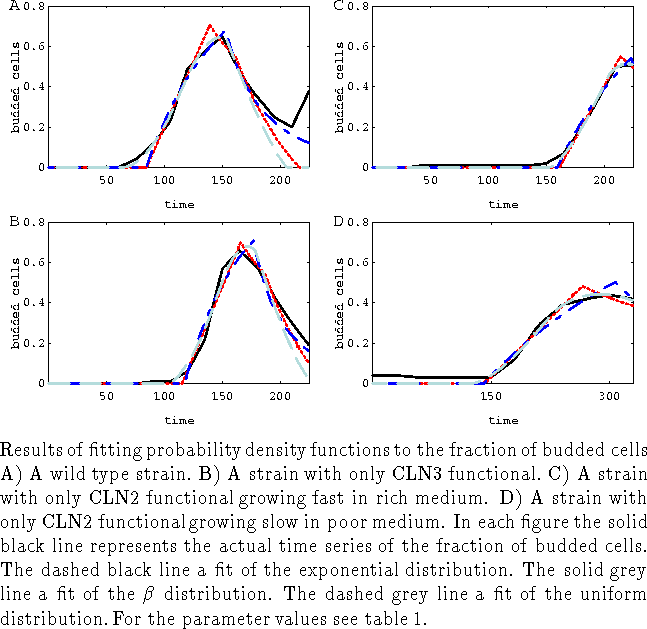
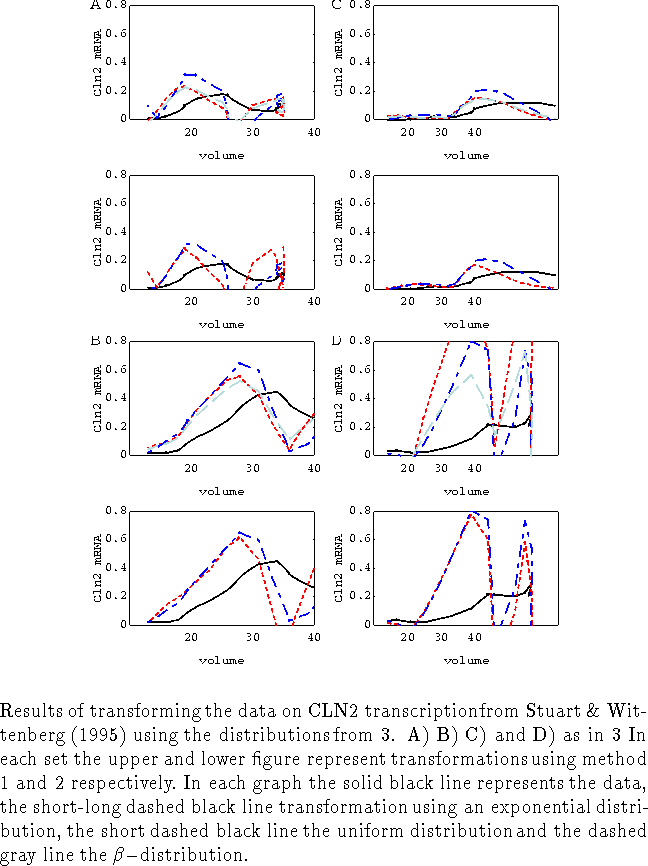
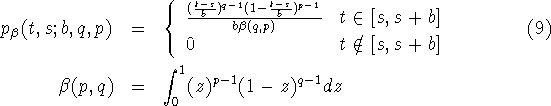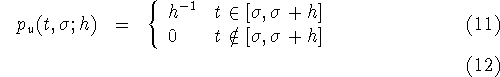In this section we will apply our synchronization methods to experiments in various strains of budding yeast cells (from Stuart & Wittenberg (1995)) measuring the time courses of CLN2 mRNA and fraction of cells having a bud. CLN2 mRNA is synthesized at the G1-S transition (referred to as Start) which is thought to be under control of cell size. The subsequent rise in CLN2-dependent kinase activity allows cells to form buds. In these experiments cells are synchronized by elutriation and selection of the smallest cells. Time series for the fraction of budded cells show that synchrony is not 100 % (fig. 1,2 and 3) and varies for the different strains.
In comparing the time series for CLN2 transcription in different strains we
have to take into account their difference in synchrony. The loss of
synchrony can have various origins: stochastic and/or deterministic
pre-Start variability and stochastic and/or deterministic post-Start
variability. In the following we assume that post-Start variability is
absent. Therefore the variability measured at the time of budding reflects
that at the time of Start. From the time series of the fraction of budded
cells we estimate probability density functions to use for synchronization
method 1 and 2. Since the cell cycle generally has a fixed length, a
probability density function defined on a fixed time interval seems the most
reasonable. For this reason we fit a ![]() -distribution
-distribution
with moments (see Kalbfleisch, 1979)
![]()
(its mirror image ![]() will be used in method 1), and a
uniform distribution
will be used in method 1), and a
uniform distribution
with moments
![]()
to the time series of the fraction of budded cells. The parameters s and ![]() displace the distributions to the moment of first appearance of
buds. The parameters b and h denote the width of the distribution. In
order to see how sensitive the transformation results are with respect to
the choice of probability distribution we also fit an exponential
distribution
displace the distributions to the moment of first appearance of
buds. The parameters b and h denote the width of the distribution. In
order to see how sensitive the transformation results are with respect to
the choice of probability distribution we also fit an exponential
distribution
to the time series. The time series of the fraction of budded cells (figs.
1,2-B and 3) are
cumulative functions of the underlying distribution. Furthermore the series
are also blurred by the fact that cells divide and re-execute the cell
cycle. Entry in the next cycle is different from the first since mother and
daughter cells behave differently. We therefore cannot use all the data and
we have to discard those data points which might contain second generation
cells which started budding. If we assume the budded interval fixed for all
cells in a strain we actually can fit this as an extra parameter to the
model. If ![]() is the cumulative probability of one of the distributions
then the time series of the fraction of budded cells
is the cumulative probability of one of the distributions
then the time series of the fraction of budded cells ![]() (to the
moment second generation buds start appear) is represented by
(to the
moment second generation buds start appear) is represented by
where B is the length of the budded period, and
In the particular experiment displayed in fig. 1-B the time series is too short to make a proper estimate of B. We therefore rely on the results of two other experiments (wild type strain and functional CLN3 strain 3-A,B) which grow in the same medium to get an estimate for B.
The fits of the distributions to the data (fig. 3, and table 1) were performed with the Mathematica@ function FindMinimum on the sum of squares
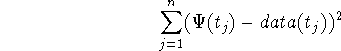
where ![]() was chosen as the first time point passed the peak of the
fraction of budded cells. Fitting the uniform and the exponential
distribution involves estimating 3 parameters
was chosen as the first time point passed the peak of the
fraction of budded cells. Fitting the uniform and the exponential
distribution involves estimating 3 parameters ![]() , and
, and ![]() respectively. Fitting the
respectively. Fitting the ![]() distribution involves estimating 5
parameters B,s,b,p,q, but since the FindMinimum function gave erratic
answers when all parameters were allowed to vary, we fixed the value of p
to 1.2.
distribution involves estimating 5
parameters B,s,b,p,q, but since the FindMinimum function gave erratic
answers when all parameters were allowed to vary, we fixed the value of p
to 1.2.
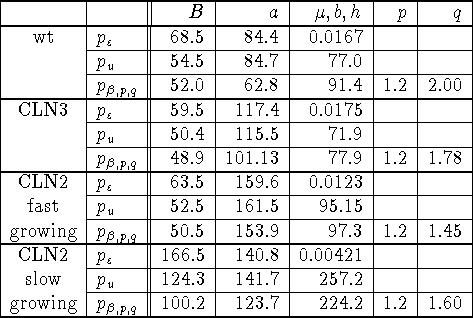
Table 1: Parameter values estimated for the various probability
distributions.
Next the fitted distributions were used in synchronizing, with either method 1 or 2, the time series of average CLN2 mRNA to time series supposed to represent individual behavior (see appendix C for method). Again we are only interested in the output of the first generation of cells and we have to cut off our time series at the moment the second generation of cells are likely to pass Start. However, we decided to perform the transformations on the whole time series (figs. 1, 2-C and 4), and leave cutting off the series to the reader's judgement. In all cases including derivatives of higher order than three did not change the synchronization results much.
All graphs in fig. 4 show a decrease in the width of the CLN2 transcription dynamics after transformation. However, none of the strains growing at the same rate (figs. 4 A,B,C) show equal CLN2 transcription dynamics, whatever synchronization scheme chosen. Figures 1,2-C and 4 show that the choice of distribution does not lead to astonishing differences. For these particular experiments the choice of transformation method does not lead to major differences. However this result cannot be generalized. In appendix B we show that one can make severe mistakes if one apply either method on output generated by assumptions made for the other. In general one is safe to apply either method when there is a perfect synchrony, or when the output shows a lack of history, the latter meaning that the output function starts of as a horizontal line. In the experiments presented here the latter case applies predominantly.